si je te revois encore bourré dans mon club, je te permaban
Hello les déglingos, Un truc qui me soule pas mal (ça commence souvent comme ça mes articles, t’a remarqué ?), c’est de trainer des computes quand on est dans l’idée de faire un reverse proxy pour protéger un kube par exemple.
Mais dit moi Jammy, pourquoi je m’emmerderais avec un reverse proxy ?

Kubernetes ça coûte cher, si on met de l’autoscaling sur les nodes, on aimerait le plus possible en avoir pour notre argent et éviter au maximum de faire de la réponse de load sur des attaques DOS nuls et consommer du cash sur des petits cons. (tu sais, les enfants qui utilisent des scripts)
Tu vas me dire un Cloudflare devant et c’est réglé. Oui, mais aujourd’hui on fait sans, on part dans l’idée de se passer de Cloudflare et de gérer notre sécu autrement. Une bonne pratique à mettre en place, mettre un reverse proxy pour ban des IPs, ou utiliser Cloud Armor directement quand c’est encore gérable humainement.
Plus d’info sur Cloudflare
Cloudflare est un outil en SAAS qui permet de protéger ton point d’entrée d’infra. Il fait protection anti DDOS, WAF applicatif et cache CDN. C’est un genre de méga couteau suisse de la sécu, qui est très utile pour faire une première couche de sécu à pas cher.
Plus d’info sur Cloud Armor
Cloud Armor est un service managé qui est une protection de type Firewall de niveau 7. On sort un peu du contexte de l’article, mais maintenant ça fait aussi WAF et DDOS (en beta)
Plus d’info sur Reverse Proxy
Un reverse proxy est une couche réseau et/ou logiciel qui est placé en amont de l’infrastructure. On s’en sert le plus souvent comme d’une couche de filtrage et d’autorisation pour les utilisateurs en provenance du Web.
Attention concept, ce qui suit va vous étonner, surtout la 3
On part dans l’idée que ban des ranges d'IPs par pays ce n’est pas une solution pour les raisons suivantes:
- si tu es un e-commerçant, tu perds des clients potentiels si tu es en mesure de livrer dans le monde entier
- tu prives un ou des pays entiers de ton magnifique site, les bons et les mauvais consommateurs
- à l’heure des VPN grand public, les géo-restrictions n’ont plus aucun sens (cet article n’est pas sponsorisé par le VPN du nord)
- les attaques sont multiples et les attaquants s’adaptent toujours plus vite que les victimes.
Donc ce n’est pas trop con d’utiliser des technos du type achat proxy (HAproxy) (trouvable dans ta grande surface habituelle), Parlons de moteur X, tu sais le serveur HTTP open source de Russie (nginx) ou encore le fameux aif cinq (F5), mais t’as intérêt à avoir des sous et une infra qui rapporte au moins le double de ta licence pour rentabiliser ton bouzin.
Règle de base de la sécu, on ne met pas plus cher en sécurité que le coût et/ou le bénéfice du bien que tu veux protéger; Et comme on est dans les solutions débiles et simplistes on va utiliser le moteur X (nginx) et la solution de ne pas interdire (fail2ban)

Plus d’info sur Nginx
Nginx est un des deux serveurs web les plus populaires avec Apache, il permet entre autre de faire:
- reverse proxy
- serveur web statique
- proxy cache
- proxy pass (serveur frontal devant une application web par exemple)
du compute ? ouais, mais en vrai ça fait chier, on dit que je n’ai pas envie
Donc on part du postulat qu’on a un beau cluster Kubernetes régional et qu’on ne va surement pas faire un SPOF énorme devant en mettant un compute unique qui portera nginx + configuration et fail2ban.
Si on devait mettre de l’effort avec des computes, je mettrais au moins deux computes en frontal dans des régions différentes. Le truc embêtant c’est que fail2ban sera dilué entre les deux machines et du coup on aura une configuration hétérogène entre les deux computes. Une IP bannie d’un côté pourrait être autorisée sur l’autre compute jusqu’à éclater de nouveau le quota.
ça implique une complexité pas vraiment négligeable
Un Global Load Balancer , deux instances groups, les deux computes qu’il faudra gérer ensuite et mettre à jour, changer la conf tout ça tout ça… On dit que je n’ai pas envie et qu’on va faire ce que tout le monde nous dit de ne pas faire, rentrer tout ça à coup de pompe dans le cul dans Cloudrun. À voir si on peut piloter Cloudarmor directement et ban les IPs en amont, comme on est dans un contexte éphémère il faut voir à quel point Cloudrun pourra nous persister des bannissements.

Plus d’info sur fail2ban
fail2ban est un outil permettant de bannir des IPS abusives sur la plupart des outils web et Linux connus.
Plus d’info sur SPOF
Single Point Of Failure (SPOF) est une brique critique du système qui rend indisponible toute l’infra si elle est défaillante. Dans notre cas un reverse proxy sur une machine unique entrainerai l’indisponibilité totale du reste de l’infra. https://fr.wikipedia.org/wiki/Point_de_d%C3%A9faillance_uniqueOn pèse le pour et le contre ?
Contre:
- on traine un truc stateful dans Cloudrun, c’est un anti-pattern (retenez bien cette phrase, elle sublime et résume cet article)
- on doit injecter de la conf dans un container, il faudra utiliser un moyen moche de le faire
- c’est une brique sensible, il ne faut pas trop se foirer et il faut que ça soit solide
- probablement qu’il va falloir faire des trucs en dépit du bon sens pour que ça fonctionne
- globalement le consensus des utilisateurs GPC dit que c’est une mauvaise idée (mais rien au monde ne m’empèchera de le faire quand même)
Pour:
- on réduit la complexité par rapport au compute
- on utilise fail2ban et nginx qui sont des outils standard et reconnus dans l’industrie
- moins cher et autoscalable
- pas de SPOF en compute
- ça à l’air d’être un beau merdier, et j’aime ça :)

Plus d’info sur stateful/stateless
stateful -> qui à un état, par exemple des écritures sur disque dans un container stateless -> qui fonctionne sans étatIdée d’implémentation
On va probablement faire des petits bouts de trucs et les assembler ensemble (ceci est une référence à Stupeflip). Mon idée c’est de recycler cet article qui semble prometteur, mais qui me dérange sur plusieurs aspects. https://hodo.dev/posts/post-39-gcp-fail2ban-cloud-armor/
L’utilisation du redis à mon sens est superflu et le scheduling est moins efficace que de faire de la réponse directement sur évènement. L’article parle d’utiliser fail2toban, mais en fait c’est complètement faux, c’est un bout de code golang custom qui imite le fonctionnement.
Je veux un proxy avec le moins de code possible et utiliser des outils standard, pour éviter le plus possible de maintenir un truc custom.
Nous on va mettre un Nginx + fail2ban dans un Cloudrun, avec un genre de daemon en Python pour écouter les IPs bannies et les transmettres à Pub/Sub.
Ensuite on dépile les messages avec une fonction qui pourra écrire les règles dans Cloudarmor. De cette façon on agit sur évènement, on ne paye pas pour un redis qui ne fait presque rien et dans le pire des cas, si la règle fail2ban ne remonte pas, les IPs d’attaque sont quand même bloqué par fail2ban jusqu’à la reconstruction du container.
Plus d’info sur Pub/Sub
Pub sub est un service managé GCP qui est un système de queue type rabbitmq. On l’utilise en général pour envoyer des messages et les traiter de manière asynchrone par un daemon qui viendra lire les messages et faire une action. En opposition aux requêtes HTTP classiques qui sont synchrones.

Une optimisation que je vois, c’est de factoriser ensuite les règles en paquets maximums Cloud Armor. Parce que dans mon précédent article on a vu que Cloudarmor était limité sur le nombre max de règles, donc on veut factoriser et maximiser nos bans.
On peut aussi faire un mécanisme de purge pour laisser une nouvelle chance aux anciennes IPs bannies, parce que les IPs ça tourne et parce que tout le monde a le droit à une seconde chance :) Mais avant ça, on fait un payback DDOS sur chacune des IPs bannies, on retrouve les adresses de chacun et on pète les ligaments croisés :)
Ou alors on fait juste un ban de 6 mois, le temps qu’il faut à peu près pour réparer les ligaments croisés.

Dans l’idée il faudra des fichiers de conf pour fail2ban et nginx, on peut embed les fichiers de conf dans le container, c’est un peu pourri, et on perd complètement l’idée d’un container immutable. Ou alors on accepte un peu plus de complexité et on sort les confs dans un bucket GCS en lecture seule.
Pour avoir une traçabilité de la conf il faudra bien conventionner le nom des fichiers dans le bucket de l’env, je propose le classique hash du commit. En templatant ce fichier de conf on peut sur chaque envs avoir une conf différentes et une traçabilité des anciennes versions.
Je te mets un schéma ici pour comprendre un peu mieux.
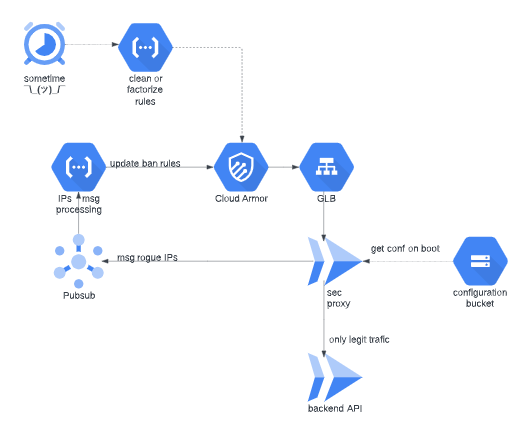
Donc on aura en point d’entrée de l’infra un Global Load Balancer, qui sert notre proxy Nginx fail2ban. Le proxy redirigera le trafic légitime vers un Cloudrun, mais ça peut être n’importe quel backend, un cluster Kubernetes, ce qui te fait plaisir Je vais mettre dedans un pluxml, pour avoir une appli de base avec une authentification sans base de données. l’appli persistera les données dans un XML en mémoire, on configurera Cloudrun pour avoir toujours le container allumé et éviter de perdre les infos de connexions à chaque requête.
Dans le proxy fail2ban on aura un Python chargé de lire l’état des jails de fail2ban et remonter les IPs des méchants dans un PubSub. Le Pub/Sub sera lu par une cloud fonction et ensuite traduit en règle de blocage Cloud Armor.
Un Cloud Scheduler sera déclenché périodiquement pour permettre de factoriser les règles de blocages et/ou de purger Cloud Armor.
Activations des API GCP
Première chose à faire, activer les API nécessaires sur notre nouveau projet.
|
|

Plus d’info sur Terraform
Terraform est un outil cloud agnostique qui permet de provisionner des ressources en d’en conserver un état.
pluxml backend et authentification
J’ai repris le Dockerfile de pluxml en virant le volume que j’ai remplacé par un dossier dans le container. Cloudrun ne prend pas en charge les volumes puisqu’il ne persiste pas de données sur disque. Dans notre cas on s’en fou un peu de la persistance, on veut juste qu’il garde les données d’auth de notre utilisateur admin suffisamment longtemps pour tenter un bruteforce de l’authentification. Pour ça on va demander à Cloudrun de laisser tourner un container en permanence pour conserver cette persistance suffisamment longtemps pour nos tests.
Tu sais, bien laisser le tout tourner comme la clim des voitures des députés toute la journée devant l’Élysée.

Container fail2ban Nginx
Pour commencer on va embed la conf au moment du build du container, pour réduire la complexité et tester notre solution. une petite ci/cd du pauvre pour réduire la fatigue manuelle qu’on connaît bien :)
Le but premier sera de tester que Nginx redirige correctement vers le backend pluxml en mode proxy pass classique.
Une fois la configuration nginx validée, on s’occupera de fail2ban.
Donc on part sur une conf nginx de noob total.
|
|
En gros on dit, tout le trafic passe sur l’URL du second Cloudrun et on met en place une limite de 10 requêtes secondes. On dit que si le quota est dépassé, on renvoie des 403 à la place de la requête légitime.
je te mets ici une implémentation passe-plat, avec de petites briques rouge du plus bel effet.

Premier problème, les routes pluxml
pluxml réécrit toutes les routes du front avec le second hostname de cloudrun (celui vers quoi on redirige notre proxy). C’est bien joli, mais ça bypass complètement l’idée du proxy. Donc du coup on va oublier cette application que je ne maitrise pas et utiliser quelque chose de beaucoup plus basique. J’ai nommé Flask l’application d’exemple toute pourrie avec un basic auth.
Ça nous permettra d’avoir un code stateless avec authentification, et comme y’a zéro front, pas de problème de réécriture de route ou de chose qui m’éloigne de mon objectif.
|
|
Comme d’habitude zéro magie, 2 logins possibles et une route hello word bateau. On est vraiment sûr de la dépouille, mais comme en frontal on a un système complexe, on s’assure d’avoir un truc simple pour s’enlever des problèmes.
Je me suis permis une petite extravagance avec la route teapot, et ouai mon pote :)
Plus d’info sur HTTP 418, i’am a teapot
C’est une blague d’informaticien un peu douteuse qui défini un code HTTP de retour 418 “je suis un pot de thé”. qui devait être une blague du premier Avril et qui est depuis resté dans la norme RFC.
https://fr.wikipedia.org/wiki/Hyper_Text_Coffee_Pot_Control_Protocol
Début d’implémentation local
On part dans l’idée de lancer Nginx, fail2ban et notre daemon Python qui va envoyer les infos.
On part dans l’idée de bloquer 3 types de comportements nuisibles:
- les floods de requêtes (attaque DOS)
- les échecs d’authentification trop nombreux (attaque bruteforce ou par dictionnaire)
- les robots un peu trop agressifs qui cherchent les routes vulnérables connues
On se fiche complet des tentatives de connexion SSH puisqu’on n’a pas de computes et si déjà on arrive à bloquer ces requêtes communes et gênantes, c’est pas mal. Comme je n’ai aucune idée de comment ça marche, on va prendre des bouts de machins et tâtonner jusqu’à ce que ça marche dans un docker local pour commencer.
Pour le moment on va juste récupérer les IPS bannis sur la jail qui est la plus probable, le flood de requête simple.
entrypoint container
|
|
le fichier de conf de la jail

J’ai pas le temps, j’suis banni, j’vais ailleurs !
|
|
le code du daemon
|
|
c’est là, c’est là, c’est la salsa du daemon

Bon encore une fois rien de spectaculaire
- on a un bout de code pour répondre au code sigterm pour que le container kill proprement.
- un appel système pour lire les IPS bannies sur la jail nginx-limit-req
En envoyant des requêtes en boucles
|
|
La première requête passe, mais comme les suivantes sont trop rapides, coup de tête dans les gencives.
Et dans le container on a un truc comme ça, donc on parvient à bloquer l’IP dans le container local, mais aussi à récupérer l’IP dans le daemon.
|
|
On fait un tour dans le container et on regarde le status de la jail
|
|
On a bien notre IP local qui est bannie
Pas de soucis si on envoie un rythme moins violent, une fois débanni.
|
|
Donc on a un bout de truc qui semble fonctionner, mais maintenant il faut que ça rentre dans Cloudrun et que ça fonctionne à l’identique.

2 ème problème la persistance fail2ban (on le savait un peu)
Notre machin marchouille localement, au moins pour le spam des requêtes simple voici le Terraform que j’ai mis en place pour le proxy
|
|
Ce qui importe, c’est les annotations knative gen2 et minscale 1
Par contre on est completement niqué sur Cloudrun à cause de la non-persistance de la base de données fail2ban. Je pensais qu’avec un CPU tout le temps allumé, on allait garder un peu la persistance, mais on peut s’assoir dessus comme une vielle paire de lunettes.
Voici l’indice qui me dit qu’on ne va pas beaucoup se marrer ….
|
|
*Fail2ban dépend d’une base de données sqlite et de la lecture des logs access et error d’Nginx. Si on n’est pas capable de persister cette info, c’est peine perdue d’essayer d’aller plus loin. On mange des erreurs de type OSerror, c’est probablement parce que notre base SQLlite n’est jamais persistée.
|
|
Les bons logs qui disent que c’est niqué José. On a bien l’info que l’IP dépasse le quota, mais à aucun moment l’IP remonte dans notre script. Donc c’est tout naze, on bloque quelques requêtes et on oublie tous dans la seconde, alzheimer proxy, yes !
Donc on va faire un choix absolument merdique avant d’être bien sûr d’enterrer l’idée, pourquoi ne pas tenter le bon vieux GCS fuse de l’enfer ?
https://cloud.google.com/storage/docs/gcs-fuse?hl=fr
On va tenter une persistance des données fail2ban dans un bucket GCS via un mapping de volume, sentez-vous cette bonne odeur ?
Je vous mets ici une référence obscure que les plus érudits reconnaitront surement ! Il faut au moins un master 2 en mémologie, et 3 ans d’expérience en internet !

Pour mettre toutes les chances de notre côté, on va utiliser la version 2 de Cloudrun, qui permet parait-il des performances réseau améliorées et full accès au filesystem. Notre montage fuse sera mis sur un bucket régional dans la même région que notre Cloudrun, pour limiter au maximum la réplication et la latence qu’on peut éviter en plus. On accroche comme point de montage la base de données de fail2ban et les logs nginx.
Je m’attends à des perfs lamentables et à une instabilité jamais inégalée, mais que veux-tu, je le fais pour la beauté du sport !
3 ème problème (mais on le savait), on utilise Cloudrun de la mauvaise façon
Avant même de tester ma dernière idée, je prends du recul et j’émets les hypothèses suivantes:
- les logs nginx et la base de données de fail2ban sont corrompus à cause de la nature éphémère de Cloudrun
- les requêtes sont rendues par Nginx et peut-être que mon daemon n’a jamais vraiment le temps de lire fail2ban
- gcsfuse dit dans la doc qu’il ne faut pas l’utiliser pour une base de données
- c’est marrant ça, sqlite c’est une base de données non ?
- des logs nginx, ça demande un temps de réponse élevée ça non ?
Je commence à comprendre pourquoi le bout de code que j’ai attrapé utilise go et redis. On va avoir un gros problème avec la latence et le besoin de sortir les IPS à bannir de Cloudrun.
Parceque les options de persistances avec Cloudrun sont:
- base de donnée cloudsql lent (base de données relationnelle),chiant,cher
- base clef valeur rapide (tcp jump + storage in memory), cher
- gcs, très lent (http jump + replication), pas cher
- firestore cher et montage nfs dans un container pas ouf
On ne veut pas un reverse proxy qui est notre point d’entrée et qui ralentit toutes nos requêtes, ce n’est pas tellement acceptable.

On lâche l’affaire ou bien ?
Alors, on fait le bilan, calmement
gcs fuze augmente la complexité de mon système et la plus-value est pas ouf:
- je dois utiliser debian en container pour utiliser fuze
- c’est possible de le faire en alpine, mais faut recompiler le binaire, la flemme de ouf
- les points de montage dans l’entry-point du container, vraiment pas fou
- inconsistance des données remontée dans GCS
- base de données sqlite inconsistante
- logs Nginx inconsistants
Et la tu vas me dire, mais putain tu es con c’est marqué dans la doc ! Oui je sais bien, mais il fallait que je teste quand même :)
Performances : Cloud Storage FUSE a une latence bien supérieure à celle d'un système de fichiers local.
De ce fait, le débit peut être réduit lors de la lecture ou de l'écriture d'un petit fichier à la fois.
L'utilisation de fichiers plus volumineux et/ou le transfert de plusieurs fichiers simultanément
contribueront à augmenter le débit.
Simultanéité : aucun contrôle de simultanéité n'est mis en place si plusieurs utilisateurs écrivent dans un fichier.
Lorsque plusieurs rédacteurs tentent de remplacer un fichier, la dernière écriture l'emporte et toutes
les écritures précédentes sont perdues.
Il n'y a ni fusion, ni contrôle de version, ni notification de l'utilisateur en cas d'écrasement ultérieur.
Disponibilité : des erreurs transitoires se produisent parfois dans des systèmes distribués tels que Cloud Storage,
entraînant une disponibilité inférieure à 100 %.
Il est recommandé d'effectuer de nouvelles tentatives en suivant les consignes indiquées sur la page Intervalle
exponentielle entre les tentatives tronquées.
Stockage local : les objets nouveaux ou modifiés seront stockés intégralement dans un fichier temporaire local jusqu'à
ce qu'ils soient fermés ou synchronisés.
Lorsque vous utilisez des fichiers volumineux,
assurez-vous que vous disposez d'une capacité de stockage local suffisante pour les copies temporaires des fichiers,
en particulier si vous utilisez des instances Google Compute Engine. Pour plus d'informations, consultez le fichier README.
Donc en gros on ce retrouve avec des fichiers inconsistants et écrasés à chaque fois, le côté fortement stateful de fail2ban pose problème.
- La base de données sqlite est probablement jamais réécrite et même si c’était le cas l’info est perdue à la prochaine réécriture.
- Les log nginx qui par essence sont fait pour être streamer dans un fichier sans latence, sont incompatible avec l’idée d’ouverture fermeture nécessaire à gcsfuse et la latence faible.
Sur le papier, ça ne marche pas, dans la pratique, ça ne marche pas, même dans ma tête ça ne marche pas :)
Alors pourquoi tu fais ça tu vas me dire ? Mais pour la gloire de Satan bien sûr :)

Rien ne va, et ce n’est que le début !
On n’a même pas commencé à écrire dans Pub/Sub, imagine le nombre de merdes qu’on a encore a géré ensuite :)
Je rappelle l’idée, utiliser des outils standard pour ne pas gérer trop de code custom et comme d’habitude, radiner à fond et faire un POC le moins cher possible :)
Je ne veux pas vous montrer que des trucs qui marche, parfois il faut s’avoir s’éclater au bitume avec classe :)
Je crois qu’on arrive au bout de l’idée, je vais essayer une dernière fois de faire marcher avec Filestore, (nfs managé) on est dans l’overkill et dans la solution de la dernière chance !
En fait, non fuck off $225.28/month, on me dit dans l’oreillette que c’est beaucoup trop cher pour un POC foireux !

Je vous ferai bien une petite imitation, mais ce n’est pas trop mon fort :)
Mon truc c’est plus les jeux de mots, je reviens, je crois qu’on a Nelson à ma porte.
Conclusion
Tu me vois venir depuis au moins 3 chapitres, ça ne marche pas et c’était un peu évident dès le début :) Je ne suis pas peu fier de livrer mon premier article certifié flingué mort-né ! On va quand même en tirer 2,3 conclusions et défoncer quelques portes ouvertes.
- Cloudrun c’est de la balle pour les charges stateless, mais quand on commence à trainer du stateful dedans, on le paye d’une façon ou d’une autre.
- Soit on déporte vers du Redis, ou du GCS, soit on continue d’écrire sur le disque comme un neuneu et on paye un Filestore qui coûte le PIB d’un micro état.
- Si on ne maitrise pas le code qu’on met dans Cloudrun, on s’expose à des emmerdes.
- Si on lance de multiples process dans Cloudrun, on risque de se faire couper la connexion au moment où le résultat de la requête HTTP est rendu.
- Cloudrun ne persiste rien en cours et moyen terme, donc on doit traiter et exporter immédiatement les données temporaires et le résultat de traitement.
- gcs fuse, c’était une mauvaise idée, c’est toujours une mauvaise idée
- il faut lire la putain de doc, même si ça fait plaisir à personne
Et donc en finalité de cet article, on traine au moins deux computes en frontal dans une zone différente si tu veux faire du reverse proxy. Et on fait un truc à base d'Ansible ou d’instance group managé avec ta conf en Terraform ¯\_(ツ)_/¯
Ou pas de reverse proxy du tout, et tu assumes de te faire péter l’infra, time to time … (en tout bien, tout honneur bien sur)
La sécu ne doit pas coûter plus cher que le truc que tu protèges !

Je vous laisse ici, échec et mat :)