Salut mes petits bots Singapouriens et lecteurs humains ! Je crois que vous ête de plus en plus nombreux à lire mes conneries et ça me fait super plaisir !
ça fait un petit moment que j’ai plus trop joué avec Kubernetes, j’ai envie de faire des trucs avec GKE autopilot.
La dernière fois j’avais tenté de l’utiliser pour faire des runners gitlab en mode auto scale,
j’ai été un peu déçu par sa vitesse de scheduling des pods et j’était pas très content de la complexité induite par rapport au service rendu.
J’ai envie de me replonger dedans, parce que les promesses de l’autopilot en termes de coût semblent avantageuses (10 centimes de l’heure pour le contrôleur et paiement à la consommation de pods).
Je vais créer un service FastAPI basique pour le faire rentrer dans Cloudrun et GKE autopilot et le stresser un peu avec Locust pour voir comment ça réagit !
Ça fait un petit moment que j’ai plus trop touché à Kubernetes, puisque Cloudrun est mon jouet préféré, mais je me remets un peu dans le bain pour mettre à jour mes pratiques !
J’en profite pour regarder ArgoCD qui semble être le nouveau produit montant dans l’écosystème Kubernetes.

Plus d’info sur ArgoCD
ArgoCD est un outil de déploiement continu pour Kubernetes qui permet aux équipes de livrer rapidement et en toute sécurité des applications dans un environnement Kubernetes. Il est conçu pour rendre la gestion et la synchronisation des ressources Kubernetes plus facile et plus efficace.
ArgoCD dispose d’une interface utilisateur Web conviviale qui facilite la visualisation et la gestion des applications déployées.
source : https://www.kaliop.com/fr/argo-cd-principes-et-fonctionnement
Une API et plus vite que ça !
Voici le service Fastapi que je vais mettre en place sur cloudrun et autopilot.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
import os
import uvicorn
import signal
from fastapi import FastAPI
api_root_path = os.getenv("ROOT_API_PATH", "/api")
app = FastAPI(
openapi_url=f"{api_root_path}/openapi.json",
docs_url=f"{api_root_path}/docs",
redoc_url=f"{api_root_path}/redocs",
)
@app.get(f"{api_root_path}/")
async def root():
return {"message": "Hello World"}
@app.get(f"{api_root_path}/slow_route")
async def slow_route():
for x in range(1, 999999):
pass
return {"message": "Hello World"}
@app.on_event("startup")
def startup_event():
signal.signal(signal.SIGINT, shutdown_handler)
signal.signal(signal.SIGTERM, shutdown_handler)
def shutdown_handler(signum, frame):
"""
Custom signal handler to gracefully shutdown the server.
"""
print("Received signal:", signum)
# Perform any cleanup or finalization tasks here
# Stop accepting new connections
uvicorn.server.Server.should_exit = True
@app.get("/readiness", include_in_schema=False)
async def ready():
return "ok"
# service can handle trafic on probes time,
#you can add database check connection and database pool exhaustion.
@app.get("/liveness", include_in_schema=False)
async def live():
return "ok" # service is running
|
Quelques explications s’imposent :)

On a mis deux routes hello word basiques juste pour avoir un service qui fonctionne au minimum.
La route slow_route permet de simuler une route un peu longue avec une charge prédictible, pour que le CPU puisse être un peu stressé et que les performances se dégradent en cas de charge.
On va faire des tests de charges par-dessus, ensuite donc on veut simuler un semblant de load.
On veut pouvoir paramétrer un root path pour faciliter le routage de nos services avec Nginx ingress s’ils ont construit tous nos services sur le même modèle.
On met en place les deux routes liveness et readiness pour Kubernetes + une logique de gestion des signaux d’arrêts pour le scheduler de kube.
Pas d’efforts particuliers pour l’authentification, puisque le service ne fait absolument rien, on s’en fout, hihihi.
Voici le Dockerfile associé
1
2
3
4
5
6
7
8
9
10
11
12
|
FROM python:3.11
EXPOSE 8080
RUN apt update && apt upgrade -y
RUN pip3 install pipenv
COPY . .
RUN useradd -ms /bin/bash fastapi
RUN chown -R fastapi:fastapi /app
USER fastapi
WORKDIR /app
RUN pipenv install
CMD ["pipenv","run","uvicorn", "main:app", "--proxy-headers", \
"--host", "0.0.0.0", "--port", "8080", "--lifespan", "on", "--timeout-graceful-shutdown", "10"]
|
Rien de magique, juste on pense a ajouter des options pour la gestions du sigterm de kube –lifespan –timeout-graceful-shutdown.
J’ai quand même mis un utilisateur non privilégié parceque c’est une bonne pratique de sécu et que ça ne demande pas vraiment d’effort particulier pour le faire :)
Cloudrun, pas trop de difficultées
Je build avec gitlab-ci et GCP cloud build, voici le Yaml pour le build et le deploy
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
image: google/cloud-sdk:latest
variables:
FASTAPI_DOCKER_IMAGE: "europe-west9-docker.pkg.dev/$GCP_PROJECT/$GCP_PROJECT/fastapi:$CI_COMMIT_SHORT_SHA"
docker_build:
stage: build
script:
- gcloud auth activate-service-account --key-file "$GOOGLE_APPLICATION_CREDENTIALS"
- gcloud config set project "$GCP_PROJECT"
- echo $FASTAPI_DOCKER_IMAGE
- gcloud builds submit . --tag "$FASTAPI_DOCKER_IMAGE"
tf_apply_cloudrun:
dependencies:
- "docker_build"
image:
name: "hashicorp/terraform:latest"
entrypoint : ['']
stage: deploy
script:
- export GOOGLE_APPLICATION_CREDENTIALS=$GOOGLE_APPLICATION_CREDENTIALS
- cd terraform/*_cloudrun_fastapi
- source ../export_env.sh
- export TF_VAR_docker_fastapi_image=$FASTAPI_DOCKER_IMAGE
- terraform init
- terraform apply --auto-approve
|
Bon je vous mets le **terraform** ici, mais il n'y a pas vraiment de difficulté pour mettre mon service en place sur cloudrun.
Pas de secrets, pas de variables, on build l’image et on la run !

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
locals {
cloudrun_roles = [
"roles/run.invoker", # calling itself
]
}
data "google_iam_policy" "noauth" {
binding {
role = "roles/run.invoker"
members = [
"allUsers",
]
}
}
resource "google_service_account" "cloudrun_fastapi" {
account_id = "cloudrun-fastapi"
display_name = "Service Account cloudrun fastapi"
}
resource "google_project_iam_member" "cloudrun_iam_bindind" {
count = length(local.cloudrun_roles)
project = var.project
role = local.cloudrun_roles[count.index]
member = "serviceAccount:${google_service_account.cloudrun_fastapi.email}"
}
resource "google_cloud_run_service" "fastapi" {
name = "fastapi"
location = "europe-west9"
template {
metadata {
labels = {
"techno" = "cloudrun"
}
}
spec {
containers {
image = var.docker_fastapi_image
}
service_account_name = google_service_account.cloudrun_fastapi.email
}
}
}
resource "google_cloud_run_service_iam_policy" "noauth" {
location = google_cloud_run_service.fastapi.location
project = google_cloud_run_service.fastapi.project
service = google_cloud_run_service.fastapi.name
policy_data = data.google_iam_policy.noauth.policy_data
}
|
Sans surprise le truc tourne !
Si vraiment on veut faire un service backend propre,
On peut mettre en place un global LB qui porte le nom de domaine et un certificat google et faire des règles de redirections vers un ou plusieurs Cloudruns avec des url rewrite.
Mais là on s’en fout, je vais utiliser l’entrypoint auto généré pour faire des tests de charges et comparer avec mon gke autopilot.

Quelques éléments à charges
On va utiliser Locust pour charger Cloudrun et pour nous faire une courbe de charge qui va nous servir de comparaison avec autopilot.
Voici mon locustfile ultra simple, on va requêter /api et /api/slow_route pour avoir une route instantanée et une route qui vas prendre du lag avec de la charge.
1
2
3
4
5
6
7
8
9
10
|
import time
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def hello_world(self):
self.client.get("/api/")
self.client.get("/api/slow_route")
|
on va partir avec des réglages un peu brutaux :
- 1500 utilisateurs
- incrément de 10 utilisateurs par seconde
- pendant 3 minutes
Voici le résultat brut de locust
Mon code sur cloudrun a absorbé environs 60000 requêtes en 3 minutes et à foiré 2 requêtes étrangement
Ce qui est incroyable, mais mon code ne fait rien donc bon ;)
1
2
3
4
5
6
|
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------|-------|-------------|-------|-------|-------|-------|--------|-----------
GET /api/ 28130 1(0.00%) | 903 25 4454 810 | 155.11 0.01
GET /api/slow_route 27665 1(0.00%) | 1364 40 4492 1100 | 152.54 0.01
--------|----------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 55795 2(0.00%) | 1131 25 4492 920 | 307.65 0.01
|
Voici la courbe d’autoscale de cloudrun (tronquée pour la visibilité), on commence à 1 containers tranquillement et ils montent jusqu’à 65 containers dans le plus grand des calmes …

Ce qui lui permet tranquillement d’absorber l’ensemble des requêtes et de downscale pratiquement immédiatement sans aucun setups particulier de ma part ce qui est impressionnant de simplicité et de puissance pour le coup.
voici la courbe de charge Locust
le nombre de requêtes rendues par seconde est presque linéaire par rapport à la rampe d’utilisateurs , le temps de réponse commence a merder à partir de 400 requêtes simultanées puis se stabilise jusqu’à la fin du temps.
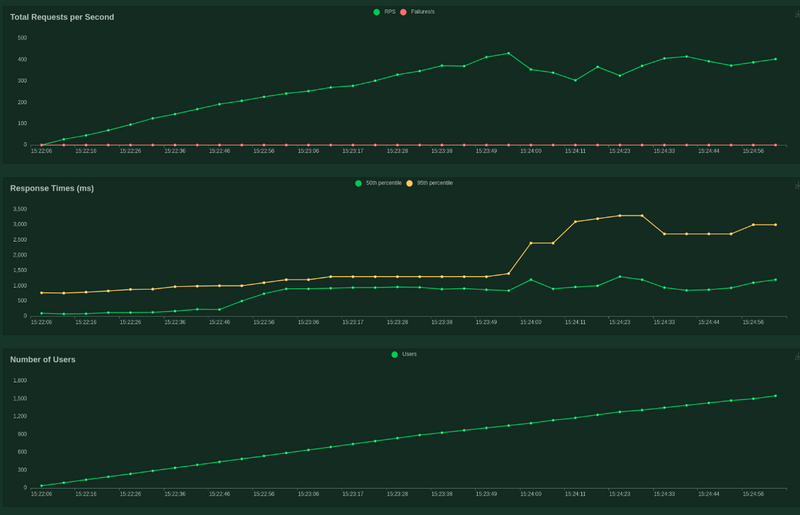
Donc quand Fastapi commence à tousser, Cloudrun compense fortement pour rendre plus de requêtes en popant des containers à la vitesse de l’éclair.

Ceci étant dit, je vais faire un setup autopilot, mais je ne vais pas autoriser autant de pods en autoscale, donc forcément le cluster autopilot aura un handicap, mais on vas quand même faire une comparaison le plus juste possible avec un setup correct pour voir ce que l’autopilot peut nous apporter.
On sait qu’on va perdre des requêtes et qu’on n’aura jamais des perfs aussi bonnes, mais ce qui nous intéresse c’est de voir la capacité d’absorption et la rapidité de scaling de l’autopilot.
K3d pour faire un cluster kube local rapidos
Comme j’ai pas envie de cramer des sous inutilement, je vais faire un cluster local avec k3d pour valider mes yaml avant de sortir les sous.
C’est une opportunité pour bricoler un peu avec ArgoCD et faire une découverte rapide de l’outil.
En vrai le tuto sur le site d’ArgoCD est tellement bien fait que je ne vais pas vous faire l’affront de le reprendre mot pour mot ici, ça n’apporte rien de plus !
Je passerai par le port forwarding de kube pour accéder au service et j’utiliserai le mode pull d’ArgoCD.
Je ne vais pas vous mettre non plus un copier-coller de l’installation et la création de cluster de k3d.
https://k3d.io/v5.5.1/
plus rapide que A-train sous compose V

Voici l’organisation des manifest kustomize que je vais mettre en place sur mon repo.
Plus d’info sur Kustomize
Traduit depuis le produit officiel
Kustomize vous permet de personnaliser des fichiers YAML bruts, sans template, pour plusieurs utilisations, tout en laissant le fichier YAML original intact et utilisable tel quel.
Kustomize cible Kubernetes ; il comprend et peut modifier des objets Kubernetes de son API. C’est comme make, dans la mesure où ce qu’il fait est déclaré dans un fichier, et c’est comme sed, dans la mesure où il émet du texte modifié.
source : https://github.com/kubernetes-sigs/kustomize
1
2
3
4
5
6
7
8
9
10
11
12
13
|
├── kustomize
│ ├── base
│ │ ├── deployment.yaml
│ │ ├── kustomization.yaml
│ │ ├── ns.yaml
│ │ └── svc.yaml
│ └── overlays
│ ├── dev
│ │ └── kustomization.yaml
│ ├── gke_autopilot
│ │ ├── hpa.yaml
│ │ ├── ingress.yaml
│ │ └── kustomization.yaml
|
Ça n’a pas trop de sens que je copie-colle mes gros yaml ici, mais je vais vous donner les infos de setup que j’ai mis.
déploiement 3 replicas
les ressources et les probs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
livenessProbe:
httpGet:
path: /liveness
port: 8080
failureThreshold: 3
periodSeconds: 30
readinessProbe:
httpGet:
path: /readiness
port: 8080
failureThreshold: 3
periodSeconds: 5
resources:
limits:
cpu: 1
memory: "200Mi"
requests:
cpu: "100m"
memory: "200Mi"
|
Donc des probes de liveness large, readiness un peu plus serrée, et des ressources suffisantes pour éviter les OOMKill et du throttling CPU trop fort.
Plus d’info sur OMMKill
Le mécanisme OOM killer (Out-Of-Memory Killer) est un mécanisme de la dernière chance qui est incorporé au noyau Linux en cas de dépassement de la capacité mémoire. Si le système n’a plus assez de mémoire à allouer aux processus et que le swap a été lui aussi entièrement rempli alors le noyau n’a pas d’autre choix que de faire appel à son tueur à gages préféré : OOM killer.
(les pods qui dépassent leurs réserve de ram allouée sont killés sans ménagement par Kubernetes)
source :https://doc.ubuntu-fr.org/oomkiller
Plus d’info sur CPU throttling
C’est un mécanisme qui permet de limiter la consommation CPU d’un processus. Si le processus consomme plus de ressources que la limite, il est mis en attente.
et mon overlay qui change simplement l’image
1
2
3
4
5
6
7
8
9
10
|
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
bases:
- ../../base
images:
- name: fastapi
newName: europe-west9-docker.pkg.dev/kube-revision/kube-revision/fastapi
newTag: 2c93080f
|
Ici une image de ton foie qui fait une indigestion après avoir bouffé tous les fichiers yaml.
Pour compléter le changement d’image dans la CI/CD, j’ai cédé au sed .
Je fais un remplacement du tag de l’image avec un sed et un autocommit sur le repo.
Le déploiement sera délégué par ArgoCD via le repo git directement.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
autopilot_version:
dependencies:
- "docker_build"
image:
name: debian:latest
entrypoint : ['']
stage: deploy
script:
- 'sed -i "s, newTag: .*, newTag: $CI_COMMIT_SHORT_SHA,g" kustomise/overlays/gke_autopilot/kustomization.yaml'
- apt update && apt install git -y
- git config --global user.name "Gitlab bot"
- git config --global user.email "[email protected]"
- git add --all
- git commit -m "[SKIP CI] autocommit new autopilot version"||true
- export authenticated_url=$(echo $CI_REPOSITORY_URL|sed "s,https://.*@,https://${GITLAB_AUTH_STRING}@,g")
- git push "$authenticated_url" "HEAD:${CI_COMMIT_REF_NAME}" -o skip-ci||true
|
J’ai mis en place un HPA (HorizontalPodAutoscaler) qui me semble raisonnable également.
1
2
|
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
fastapi Deployment/fastapi 4%/10% 3 10 3 6d
|
On monte jusqu’à 10 pods si le CPU alloué des pods dépasse 10% de load, ça devrait monter assez vite :)
Oh putain, c’est génial, j’ai rien compris !

Donc là je pense que j’ai perdu du monde, donc je vais vous faire un petit schéma un peu simpliste pour synthétiser mon bouzin.
Tout à gauche on à Terminator qui viens du futur pour bolosser ton CPU !
Ça sera ma machine de dev qui viendra attaquer **Cloudrun** et le cluster **autopilot** avec les tests de charges **Locust**.
Tout à droite, on à gitlab.com avec les runners public, qui sera chargé de builder les images docker via cloudbuild et cloudbuild vas pusher les images dans artifactory.
Gitlab est aussi chargé de déployer cloudrun via terraform, à chaque build d'une nouvelle image.
le runner gitlab met également à jour la version de l'image docker dans le manifest kustomize.
ArgoCD est connecté à gitlab et viens monitorer les changements de version directement dans le repo gitlab.
Si une version de l’image docker change, argocd va déployer directement cette nouvelle image.
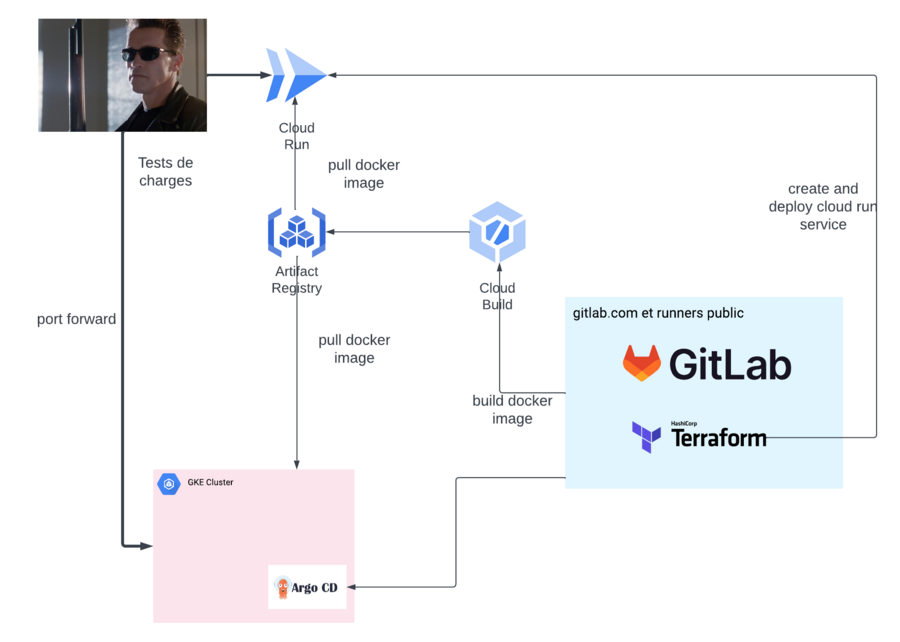
Donc maintenant ce qu’il vas nous manquer, c’est de construire le cluster Kubernetes, installer ArgoCD, le configurer pour qu’il récupère les modifications Kustomize, et ensuite on va charger à mort le cluster kube et voir comment il scale et comment il crève :)
Autopilote, encore un dernier shot
Ah c’est du propre, on fait un GKE autopilot ! c’est pour ma ville, Terraform mon pote !

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
resource "google_service_account" "gke_autopilot" {
account_id = "service-account-gke-autopilot"
display_name = "Service Account GKE autopilot"
}
resource "google_container_cluster" "primary" {
name = "gke-autopilot"
location = var.region
enable_autopilot = true
private_cluster_config {
enable_private_endpoint = false
enable_private_nodes = true
}
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
release_channel {
channel = "REGULAR"
}
timeouts {
create = "30m"
update = "40m"
}
}
|
Donc pour reprendre vite fait le setup :
- Une version de Kubernetes normale, stable, mais pas vieille au point de former une grosse croûte sur le dessus !
- le réseau des nodes en privé
- le réseau de l’API en public (je n’ai pas envie de m’embêter avec le whitelist d’IP).
- allocation réseau autogérée, parce que je n’ai aucun intérêt à le faire manuellement dans mon cas.
On applique les trucs sans s’appliquer
Je fais mon namespace et mon apply sans trop réfléchir et v’la ti pas que gke autopilot ne veux pas !
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
NAME READY STATUS RESTARTS AGE
argocd-application-controller-0 0/1 ImagePullBackOff 0 4m5s
argocd-applicationset-controller-56fd6cf449-sz626 0/1 ImagePullBackOff 0 4m7s
argocd-dex-server-6f6b565f59-5w6nz 0/1 Init:ImagePullBackOff 0 4m7s
argocd-notifications-controller-79dd749b4-fq5zs 0/1 ImagePullBackOff 0 4m6s
argocd-redis-5b584675cd-9rxzr 0/1 ImagePullBackOff 0 4m6s
argocd-repo-server-6f496c869-vmksc 0/1 Init:ImagePullBackOff 0 4m6s
argocd-server-df8cd8dc9-s4r45 0/1 ImagePullBackOff 0 4m6s
argocd-dex-server-6f6b565f59-5w6nz 0/1 Init:ErrImagePull 0 4m8s
argocd-repo-server-6f496c869-vmksc 0/1 Init:ErrImagePull 0 4m12s
argocd-dex-server-6f6b565f59-5w6nz 0/1 Init:ImagePullBackOff 0 4m20s
argocd-repo-server-6f496c869-vmksc 0/1 Init:ImagePullBackOff 0 4m26s
argocd-applicationset-controller-56fd6cf449-sz626 0/1 ErrImagePull 0 4m36s
argocd-server-df8cd8dc9-s4r45 0/1 ErrImagePull 0 4m40s
argocd-application-controller-0 0/1 ErrImagePull 0 4m40s
argocd-applicationset-controller-56fd6cf449-sz626 0/1 ImagePullBackOff 0 4m51s
argocd-server-df8cd8dc9-s4r45 0/1 ImagePullBackOff 0 4m53s
argocd-application-controller-0 0/1 ImagePullBackOff 0 4m55s
argocd-redis-5b584675cd-9rxzr 0/1 ErrImagePull 0 5m12s
|
ah CKC
1
2
3
4
|
Warning Failed 97s (x2 over 3m54s) kubelet Failed to pull image
Warning Failed 83s (x6 over 4m54s) kubelet Error: ImagePullBackO
Normal BackOff 68s (x7 over 4m54s) kubelet Back-off pulling imag
Normal Pulling 16s (x5 over 5m24s) kubelet Pulling image "quay.i
|
Alors, comment te dire que chez moi je n’ai pas de problème de pull image ?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
docker pull quay.io/argoproj/argocd:v2.7.6
v2.7.6: Pulling from argoproj/argocd
837dd4791cdc: Pull complete
136f3a22b460: Pull complete
31204270110a: Pull complete
73f4b98c99bf: Pull complete
39ae424a14e9: Pull complete
eb04a9937352: Pull complete
8150baa0eb71: Pull complete
180f0aecdf8a: Pull complete
4fc4c0f2d52f: Pull complete
10e970e39f41: Pull complete
4f4fb700ef54: Pull complete
bee43e332c56: Pull complete
ea93eb747fec: Pull complete
c47bef8dcfa0: Pull complete
Digest: sha256:7daba5f38b23f4f091951b727db6f87dc04ad396fd21044401502438d633836e
Status: Downloaded newer image for quay.io/argoproj/argocd:v2.7.6
quay.io/argoproj/argocd:v2.7.6
|
Qu’à cela ne tienne, possiblement, un truc que je n’ai pas lu dans le doc qui dit que seules les images des registres Google sont reachable par défaut.
(spoiler alerte : hypothèse fausse réfutée par la suite)
Alors on va faire du sale à base de awk et de grep hey !
On va faire des p’tits bouts d’scripts et puis les assembler ensemble et compiler tout ça tranquille dans ma chambre !

1
2
3
4
5
6
7
8
9
10
11
12
|
#!/bin/bash
set -x
curl -O https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
for image in $(cat install.yaml|grep image:|sort -u|awk '{print $2}') ;
do
image_name_tag="${image##*/}"
docker pull $image
docker tag $image europe-west9-docker.pkg.dev/kube-revision/kube-revision/$image_name_tag
docker push europe-west9-docker.pkg.dev/kube-revision/kube-revision/$image_name_tag
sed -i "s,$image,europe-west9-docker.pkg.dev/kube-revision/kube-revision/$image_name_tag,g" install.yaml
done
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
+ curl -O https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 948k 100 948k 0 0 5362k 0 --:--:-- --:--:-- --:--:-- 5386k
++ cat install.yaml
++ grep image:
++ sort -u
++ awk '{print $2}'
+ for image in $(cat install.yaml|grep image:|sort -u|awk '{print $2}')
+ image_name_tag=dex:v2.36.0
+ docker pull ghcr.io/dexidp/dex:v2.36.0
v2.36.0: Pulling from dexidp/dex
Digest: sha256:1139d90561f8e12e6c1187e60097afd7d1096f7906776e450c1941890c3eae32
Status: Image is up to date for ghcr.io/dexidp/dex:v2.36.0
ghcr.io/dexidp/dex:v2.36.0
+ docker tag ghcr.io/dexidp/dex:v2.36.0 europe-west9-docker.pkg.dev/kube-revision/kube-revision/dex:v2.36.0
+ docker push europe-west9-docker.pkg.dev/kube-revision/kube-revision/dex:v2.36.0
The push refers to repository [europe-west9-docker.pkg.dev/kube-revision/kube-revision/dex]
bbffe310657c: Layer already exists
95fe87830f34: Layer already exists
efa0be046a65: Layer already exists
e7cee029c41e: Layer already exists
65d5ca5dc5eb: Layer already exists
8a2a397517e7: Layer already exists
5394d6490187: Layer already exists
129291c1a9eb: Layer already exists
a9cd78ad1450: Layer already exists
7cd52847ad77: Layer already exists
v2.36.0: digest: sha256:4112b9bab55bc1cc1e795687e158d029f4cf2db2dde74898bb372f99ccc31c31 size: 2413
+ sed -i s,ghcr.io/dexidp/dex:v2.36.0,europe-west9-docker.pkg.dev/kube-revision/kube-revision/dex:v2.36.0,g install.yaml
+ for image in $(cat install.yaml|grep image:|sort -u|awk '{print $2}')
+ image_name_tag=argocd:v2.7.6
+ docker pull quay.io/argoproj/argocd:v2.7.6
v2.7.6: Pulling from argoproj/argocd
Digest: sha256:7daba5f38b23f4f091951b727db6f87dc04ad396fd21044401502438d633836e
Status: Image is up to date for quay.io/argoproj/argocd:v2.7.6
quay.io/argoproj/argocd:v2.7.6
+ docker tag quay.io/argoproj/argocd:v2.7.6 europe-west9-docker.pkg.dev/kube-revision/kube-revision/argocd:v2.7.6
+ docker push europe-west9-docker.pkg.dev/kube-revision/kube-revision/argocd:v2.7.6
The push refers to repository [europe-west9-docker.pkg.dev/kube-revision/kube-revision/argocd]
5771e8f35ae5: Pushed
0a5fda927edf: Pushed
5f70bf18a086: Layer already exists
4ebf4623470c: Pushed
dade4926f0ce: Pushed
1f8207a0c84c: Pushed
4f70f53f4994: Pushed
eabbc05514f5: Pushed
f9c25e1080b1: Pushed
94d2f74ff2ee: Pushed
92fb30a100d3: Pushed
113c81e66172: Pushed
b71dc745a2e0: Pushed
966e94ab6e16: Layer already exists
v2.7.6: digest: sha256:6382ca349b02fa14ed64a0bf5b57b845962a5cc2d00d881e240ee2b8ed50717e size: 3444
+ sed -i s,quay.io/argoproj/argocd:v2.7.6,europe-west9-docker.pkg.dev/kube-revision/kube-revision/argocd:v2.7.6,g install.yaml
+ for image in $(cat install.yaml|grep image:|sort -u|awk '{print $2}')
+ image_name_tag=redis:7.0.11-alpine
+ docker pull redis:7.0.11-alpine
7.0.11-alpine: Pulling from library/redis
Digest: sha256:121bac949fb5f623b9fa0b4e4c9fb358ffd045966e754cfa3eb9963f3af2fe3b
Status: Image is up to date for redis:7.0.11-alpine
docker.io/library/redis:7.0.11-alpine
+ docker tag redis:7.0.11-alpine europe-west9-docker.pkg.dev/kube-revision/kube-revision/redis:7.0.11-alpine
+ docker push europe-west9-docker.pkg.dev/kube-revision/kube-revision/redis:7.0.11-alpine
The push refers to repository [europe-west9-docker.pkg.dev/kube-revision/kube-revision/redis]
00647d5bbe9e: Pushed
4e17a344e006: Pushed
7936e9b38dab: Pushed
e3b65bf0a803: Pushed
235d52d65f01: Pushed
78a822fe2a2d: Pushed
7.0.11-alpine: digest: sha256:ed439ea2fd065ac9622bf40b8bdb156e1e2bb2b73f7877f430775b8d728b3eec size: 1571
+ sed -i s,redis:7.0.11-alpine,europe-west9-docker.pkg.dev/kube-revision/kube-revision/redis:7.0.11-alpine,g install.yaml
|
savate, télé et terminé bonsoir

1
2
3
4
|
jchardon@jchardon ~/projects » cat install.yaml|grep image:| sort -u
image: europe-west9-docker.pkg.dev/kube-revision/kube-revision/argocd:v2.7.6
image: europe-west9-docker.pkg.dev/kube-revision/kube-revision/dex:v2.36.0
image: europe-west9-docker.pkg.dev/kube-revision/kube-revision/redis:7.0.11-alpine
|
au passage, pour choper le mot de passe par défaut d’ArgoCD on peut faire comme ça
1
|
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d
|
Bon c’est au moment ou j’ai voulu contacter Gitlab depuis ArgoCD que j’ai compris que y avais probablement une histoire de NAT qui m’empêchait l’accès aux internet.
Puisque j’ai fait un cluster privé mais que j’ai pas penser à router l’accès vers internet.

Au passage on vas refaire un truc un peu plus clean avec un VPC qui n’est pas celui par défaut :)
Menu classique NetworkMeal VPC + subnet + routeur + cloudnat
Tu me met un supplément fromage et chips avez ça stp !
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
resource "google_compute_network" "vpc_network" {
project = var.project
name = var.vpc_name
auto_create_subnetworks = false
}
resource "google_compute_subnetwork" "subnetwork" {
name = var.subnet_name
ip_cidr_range = "10.2.0.0/16"
region = var.region
network = google_compute_network.vpc_network.id
}
resource "google_compute_router" "router" {
name = "gke-subnet-router"
region = google_compute_subnetwork.subnetwork.region
network = google_compute_network.vpc_network.id
bgp {
asn = 64514
}
}
resource "google_compute_router_nat" "nat" {
name = "gke-subnet-nat"
router = google_compute_router.router.name
region = google_compute_router.router.region
nat_ip_allocate_option = "AUTO_ONLY"
source_subnetwork_ip_ranges_to_nat = "ALL_SUBNETWORKS_ALL_IP_RANGES"
log_config {
enable = true
filter = "ERRORS_ONLY"
}
}
|
et ensuite j’ai juste à reprendre mon code GKE et renseigner vpc et subnet et ça fonctionne sans soucis
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
resource "google_service_account" "gke_autopilot" {
account_id = "service-account-gke-autopilot"
display_name = "Service Account GKE autopilot"
}
resource "google_container_cluster" "primary" {
name = "gke-autopilot"
location = var.region
enable_autopilot = true
network = var.vpc_name
subnetwork = var.subnet_name
private_cluster_config {
enable_private_endpoint = false
enable_private_nodes = true
}
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
release_channel {
channel = "REGULAR"
}
timeouts {
create = "30m"
update = "40m"
}
}
|
Au passage, juste le provisonning de ArgoCD la consommation de ressources est pas top

Pour un poc avec 3 pods qui se courrent après … et là en plus ce n’est que la consommation d’ArgoCD, j’ai rien déployé de plus, même pas un petit nginx ingress dans un paradis fiscal ! quelle honte, quelle indignité !

Bon après quand tu as un cluster avec 30 vcpu on est plus trop à ça près, mais il faut bien réfléchir si vous en avez vraiment besoin :)
Ça vient surement du bon pote autopilot qui choisi des ressources au doigt mouillé, on peut surement réduire un peu les ressources consommées en les définissant manuellement ensuite.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
Warning: Autopilot set default resource requests for Deployment argocd/argocd-applicationset-controller, as resource requests were not specified. See http://g.co/gke/autopilot-defaults
deployment.apps/argocd-applicationset-controller created
Warning: Autopilot set default resource requests for Deployment argocd/argocd-dex-server, as resource requests were not specified. See http://g.co/gke/autopilot-defaults
deployment.apps/argocd-dex-server created
Warning: Autopilot set default resource requests for Deployment argocd/argocd-notifications-controller, as resource requests were not specified. See http://g.co/gke/autopilot-defaults
deployment.apps/argocd-notifications-controller created
Warning: Autopilot set default resource requests for Deployment argocd/argocd-redis, as resource requests were not specified. See http://g.co/gke/autopilot-defaults
deployment.apps/argocd-redis created
Warning: Autopilot set default resource requests for Deployment argocd/argocd-repo-server, as resource requests were not specified. See http://g.co/gke/autopilot-defaults
deployment.apps/argocd-repo-server created
Warning: Autopilot set default resource requests for Deployment argocd/argocd-server, as resource requests were not specified. See http://g.co/gke/autopilot-defaults
deployment.apps/argocd-server created
Warning: Autopilot set default resource requests for StatefulSet argocd/argocd-application-controller, as resource requests were not specified. See http://g.co/gke/autopilot-defaults
|
voici les étapes que j’ai dû faire pour configurer argocd
Créer un repo.
le repo est connecté.
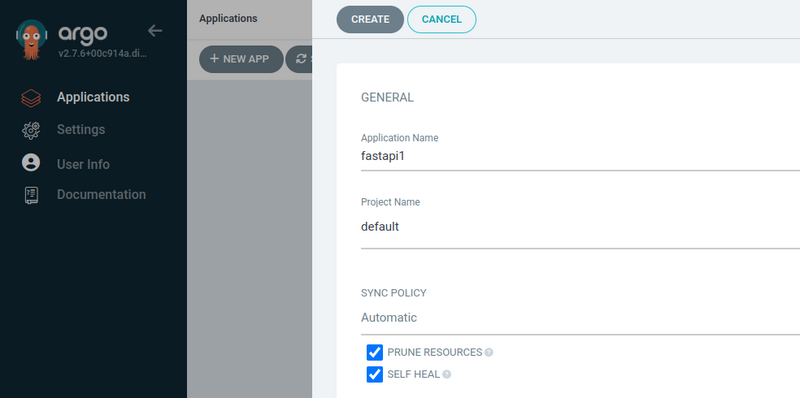
Créer une application à partir de mon repo connecté.
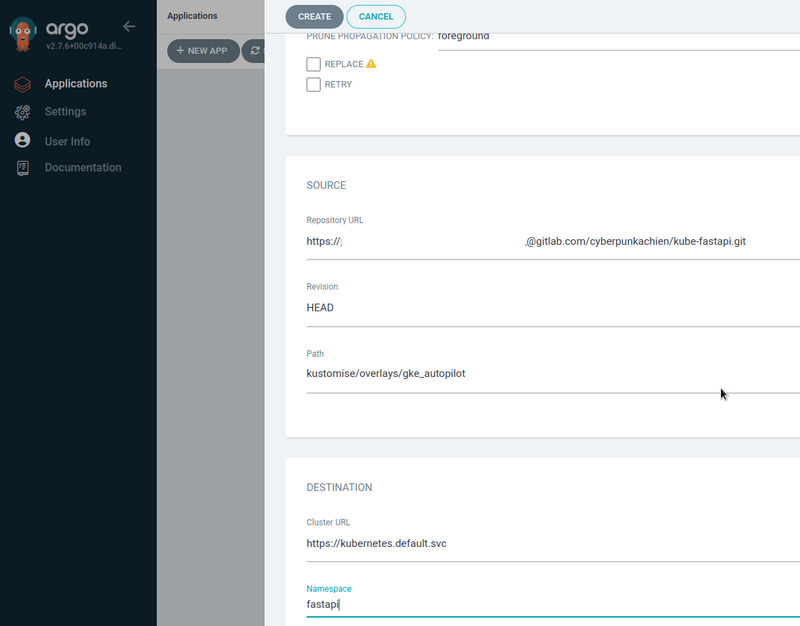
Suite de la création.
une fois l’application créée on a tout de suite une vue de synthèse qui s’affiche comme celle-ci.
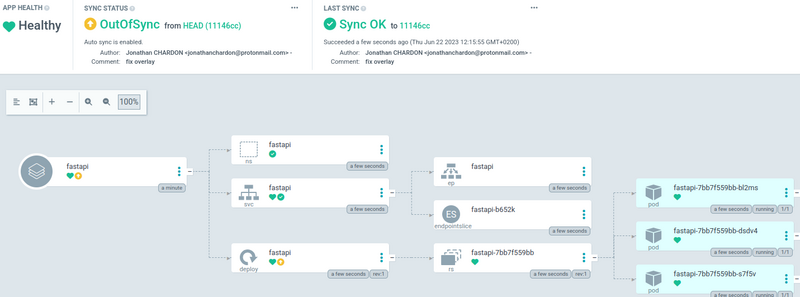
si on clique dessus on arrive sur une vue large bien plus agréable avec l’ensemble des ressources sous forme d’arbre.
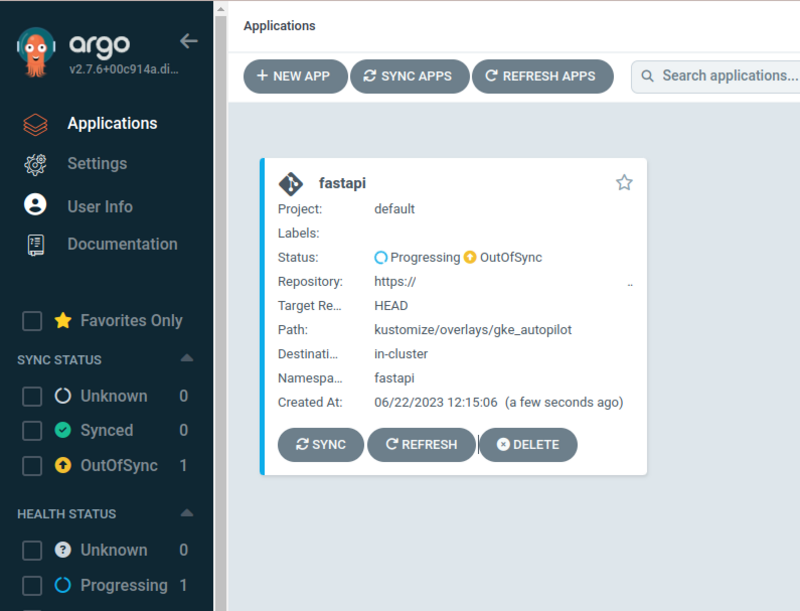
On est content, ça fonctionne enfin, j’ai mis un nginx ingress pour pouvoir accéder à mon application depuis l’extérieur du cluster.
Un rollercoaster d’émotions

J’ai mis un ingress pour requêter mon cluster kube et j’envoie la charge sur autopilot.
Voici les perfs que j’ai obtenues après toutes les galères de mise en place.
1
2
3
4
5
6
|
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|-----------------|-------|-------------|-------|-------|-------|-------|--------|-----------
GET /api/ 21778 16392(75.27%) | 1821 0 46926 18 | 120.99 91.07
GET /api/slow_route 21302 17055(80.06%) | 1684 0 47207 17 | 118.35 94.75
--------|-----------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 43080 33447(77.64%) | 1753 0 47207 17 | 239.34 185.82
|
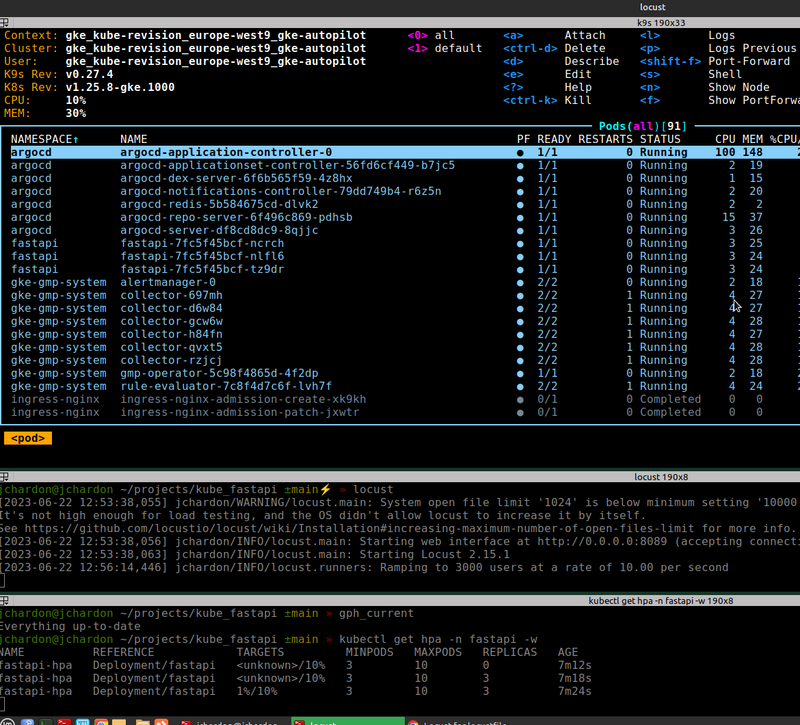
je vous ai mis des captures pour vous montrer comment je surveille mon cluster en même temps
En capacité nominale 3 pods et HPA non déclenchés
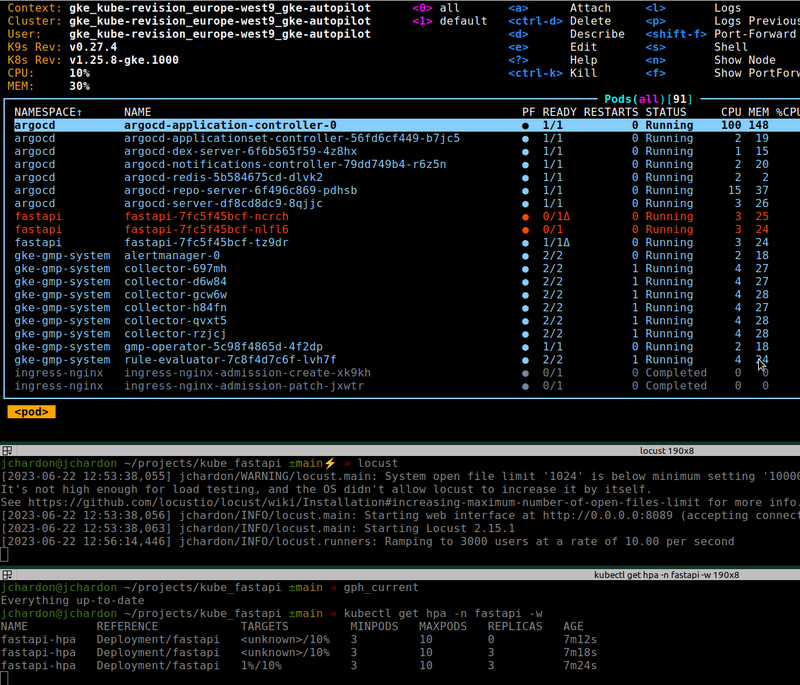
Les probes de readiness sont déclenchées, tous les pods présents sont désormais injoignables, le HPA n’est pas encore déclenché, on perd toutes les requêtes
Mais néanmoins aucun restart n’est fait, ce qui permet de gérer les quelques requêtes restantes dans les pods.
On route dans le vide, putain de bordel de merde, c’est quoi ça ?
On a déclenché les HPA jusqu’à 6 pods, mais c’est bien trop tard bob, CKC !
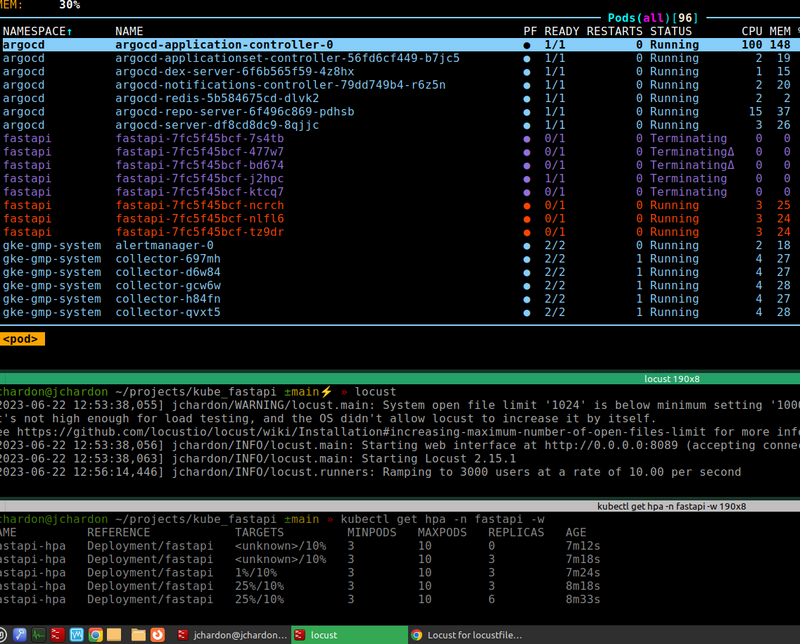
Mais c’est un vrai rollercoaster cette courbe ! rien ne vas !
Bon j’avoue la charge est bien brutale et j’aurai pu faire des rampes un peu plus cool pour ménager un peu la chèvre et le chou !
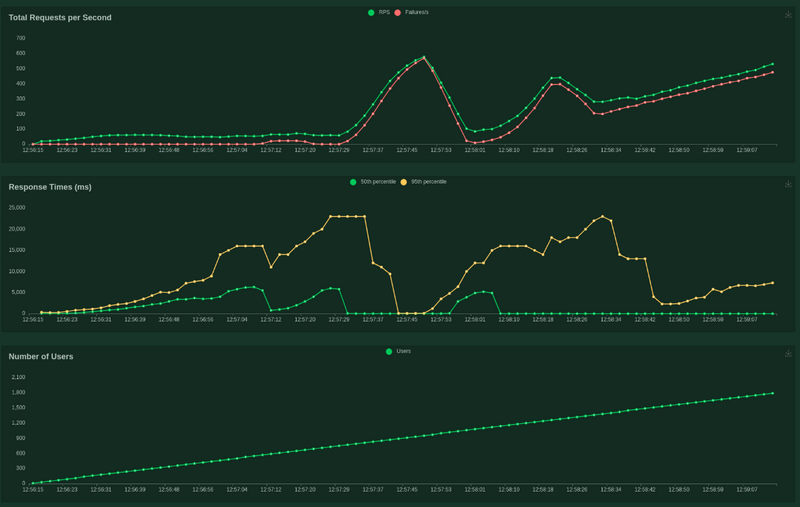
Le moins qu’on puisse dire c’est que ce n’est pas fameux par rapport à Cloudrun
78% d’échec, une courbe qui fait le rollercoster, la capacité de scaling est quand même présente,
mais la charge appliquée est trop rapide et bien trop violente pour la capacité d’absorption d’autopilot.
J’aurai pu fine tune un peu plus encore le HPA et le mettre encore plus bas, mais de toute façon le test est trop brutal et n’est pas tellement représentatif d’une vraie charge.
Donc ça scale tranquille frère, pas trop vite, pas trop fort, mais on est là !

Con Gestion et reste à charge
J’ai envie de gueuler très fort, ta mère le cloud !
Toute cette galère pour des perfs nulles et une complexité complètement débile pour 3 pods.
Clairement dans le duel autopilot vs Cloudrun, je donne Cloudrun vainqueur par KO au premier round.
Comment on peut lutter contre un service managé hyperscale qui pop des containers à volonté de son chapeau sans aucun effort particulier ?
Pas de configuration compliquée, pas besoin de connaissances poussées en réseau, en configuration ou en quoi que ce soit, amène ton container il va tourner t’inquiète.
La techno qui ne juge pas et que fait le taf.

Néanmoins certains petits trucs vont aller en faveur de Kubernetes, la gestion du réseau, le contrôle de la communication entre les containers, la gestions des containers statefull et la portabilité en font un outil puissant et incontournable.
Ce POC m’a permis de tester l’autoscaling d’autopilot dans les conditions les plus énervées possible et je dois dire que la promesse est quant à elle respectée.
Les pods ont scalé dans un délai raisonnable par rapport à un cluster kube en dur avec des noeuds déjà prêts ou autoscalables.
Ce que j’ai apprécié d’autopilot, c’est la capacité à définir des ressources par défaut de lui-même, ce qui permet un peu de charges mentales en moins.
La gestion des ressources est toujours un compromis délicat entre faire de grosses machines qui coûtent cher ou plus de petites machines avec moins de pods par machines.
En termes de coût, je pense qu’on s’y retrouve complètement puisqu’autopilot n’a pas de ressources en attente dans les nodes qui attendent sans rien faire et qui coûtent cher.
ArgoCD réduit un peu la charge mentale de synchroniser les repos et le fait de fonctionner en mode pulling permet de prendre les yaml sous différentes sources de vérités, mais protège aussi l’admin panel kubernetes en empêchant une communication directe avec le runner de cicd.
J’aime l’idée de pouvoir utiliser du kustomize du helm et du jsonnet même si je suis team kustomize, c’est une techno qui ne juge pas, et les technos qui jugent pas, moi j’aime ça !
Le dashboard rend l’expérience Kubernetes un peu plus conviviale et graphique, et c’est surement un vrai plus quand on commence à avoir une shitload d’objets à gérer.
C’est sans aucun doute un très bon outil, à qui prend la peine de le comprendre et de le configurer.
Le mot de la fin, encore un poc de gros radin !
Ça ne m’a pas coûté un radis, parce que je n’ai pas laissé tourner mes ressources et que j’ai largement bénéficié du free tier GCP.
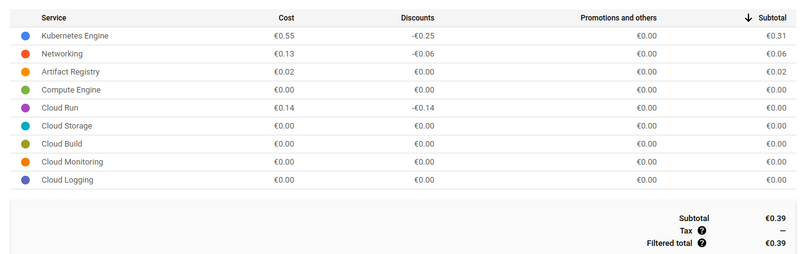
Je vous laisse, je vais faire du cloudrun dans la piscine hihihi
merci à Romain Poncet pour les corrections :)