Je te donne mes astuces gitlab
Hello ici, je n’ai pas trouvé de titre rigolo cette fois-ci, mais on part sur un article efficace. Je te balance en vrac les trucs que j’ai pu expérimenter avec gitlab, y’aura à boire et à manger comme d’hab. Des trucs que j’ai faits chez des clients (mais j’ai réécrit tout le code, ce n’est pas du vol, ne pas poursuivre) et des idées qui ont germé de mon cerveau malade.
On va s’enjailler en tabarnak, Tequila, Heineken, pas le temps de niaser !

backup sécurisé des variables gitlab-ci
Un truc que j’ai toujours trouvé un peu frustrant sur Gitlab, c’est le manque de traçabilité des actions manuels. C’est quand même super con de faire des efforts pour versionner du code de l’infra, le code, les pipelines, mais qu’on risque de tout casser en faisant un changement manuel. Par exemple un secret gitlab que tu modifies ou que tu supprimes par erreur et c’est toute ta chaine de build qui peut être cassé.
Pourquoi ne pas profiter des API de Gitlab et du système de versionning de repo pour faire un backup versionné des variables Gitlab ? Mais bien entendu on va chiffrer les secrets avec une clef GPG pour que les variables ne soient pas versionnées en clair dans le repo.
Plus d’info sur GPG
l’idée de la clef GPG c’est d’utiliser un chiffrage fort et standard sur les secrets versionnés dans git pour que si le repo est intercepté par un malandrin, il ne puisse pas te voler tes secrets.
l’idée du chiffrement asymétrique c’est qu’on peux aussi révoquer et ajouter plusieurs clefs si besoin. Je te met ici la littérature sur GPG si tu veux en savoir plus:
Boucle bien ta ceinture, tu n’es pas près pour la prochaine connerie :)

Parce que c’est la France, le pays de l’élégance ! et parfois de l’arrogance (dédicace à Bobby)
On va utiliser git-crypt pour chiffrer les secrets, mais pour éviter les confusions franco linguistique des plus français d’entres nous, nous allons renommer cette commande en utilisant des alias.
|
|
Pour les plus septiques d’entre vous, je vous renvoie vers ce lien d’une importance capitale pour la francophonie. https://chiffrer.info/
Pour la visibilité des changements, on va générer un fichier en clair avec un md5 des valeurs des clefs, afin de facilement détecter les changements sans avoir besoin de tout le temps déchiffrer le fichier de backup.
On va profiter du python SDK de Gitlab en utilisant un utilisateur robot admin avec un token API. C’est très important d’utiliser un user technique pour des taches admin afin que les trucs que tu as mis en place marche toujours, parce que le jour où tu pars et qu’on désactive ton compte, les collègues seront bien emmerdés à chercher quel token correspond à quel compte.
On va faire un truc un peu comme ça
|
|
Truc un peu idiot, on va utiliser une clef GPG qui sera dans les secrets Gitlab. (tu devrais en garder une copie dans un vault ailleurs au cas où) On part du principe que si tu peux lire les secrets Gitlab de ce projet, tu as les droits admin pour pouvoir lire toutes les variables. Donc la protection des secrets du repo tient à trois choses:
- ne pas laisser trainer la clef de déchiffrement sur ton poste
- restreindre au maximum les accès à ce repo de backup
- chiffrer le disque dur de ton poste pour éviter de te faire voler tes secrets si on te vole ton poste et que tu n’as pas respecté la condition #1 :)
Laisse quand même un peu de challenge au braqueur pour piquer tes secrets, sinon tu ne fais même pas une saison et tu te fais shooter devant la banque à l’épisode 1 :)

implémentation
En langue de serpent ça nous donne un truc comme ça
|
|
et je vous mets le Pipfile ici
|
|
il ne t’aura pas échappé que le script utilise 2 variables d’environnement:
- GITLAB_ADMIN_TOKEN l’api token de mon utilisateur admin
- GITLAB_ROOT_GROUP_ID l’id de ton group dans lequel ce trouve les projets que tu veux backup
/!\ pense bien à initialiser correctement git-crypt avant de commit le fichier sensible.
Un petit article de Korben ici qui explique sans ambiguïté comment faire.
https://korben.info/git-crypt-du-chiffrement-transparent-git.html
Et avec le fichier .gitattributes qui va bien
|
|
/!\ si tu as le moindre doute sur le fait que tu as commité au moins une fois le fichier en clair supprime complètement ton repo et repart d’un historique clean :)

Une fois chiffrée on devrait avoir une belle bouillie comme celle-ci
|
|
le fichier de clef md5 ressemblera à ça
|
|
Un dict par projet, un md5 de la valeur de chacune des clefs S’il y a une nouvelle clef ou un changement de valeur, il vous suffira de comparer les versions du fichier md5 pour savoir tout de suite ce qui a bougé.
Et si vraiment une valeur est corrompue ou perdue, il te faudra déchiffrer le fichier et décoder la valeur base64 de la clef. Oui c’est un peu relou, mais au moins tu sauves ton cul et ta prod !
C’est pas mortel ça ?

maintenant on va faire le fichier de ci/cd pour automatiser les backups :)
Voici le yaml des familles avec quelques astuces de sioux.
|
|
Rien de magique:
- j’installe les libs python et j’utilise python-shebang dans mon script pour utiliser le virtualenv de pipenv
- on déchiffre notre fichier d’envs
- on lance notre script python
- on set un nom et un email pour notre robot
- on add all et on en fait un commit
- on remarque le [SKIP CI] dans le message de commit
- on remplace l’utilisateur par défaut de la ci/cd pour utiliser notre token privilégié
- GITLAB_AUTH_STRING contient en fait une fstring du type “nom de mon token api” + “:” + “nom token gitlab” +"@"
- et on fait un git push qui gagne à tous les coups pour éviter de prendre une erreur Gitlab si n’y’a rien à commit
Bon maintenant on va mettre un cron Gitlab en place pour scheduler le bouzin, je fais ça manuellement. Si vous avez compris ma démarche, vous connaissez déjà la prochaine étape.
/!\ si tu utilises les environnements Gitlab et que vous avez plusieurs fois la même clef sur plusieurs envs, il faudra adapter le code pour en tenir compte. Mais je pense que si tu es ici, tu parles un peu de fourchelang, donc rien d’insurmontable !

backup des crons
On vient de mettre en place un cron Gitlab, mais ça serait vachement bien d’avoir en 1 seul coup d’œil tous les crons actifs de tous les projets et versionner tout ça un peu de la même façon.
Je fais fourcher ma langue pour vous faire ça !
2022 on fait du recyclage, on prend la même en adaptant un peu :)
|
|
Bon je vais pas faire l’affront de recopier la CI/CD, c’est pratiquement la même chose, mais sans git-crypt et avec un nom de script différent. Ça nous donne un fichier yaml de résultat comme celui-ci.
|
|
J’ai changé une lettre dans la description de mon cron et en relançant le script on voit tout de suite que quelque chose a changé.
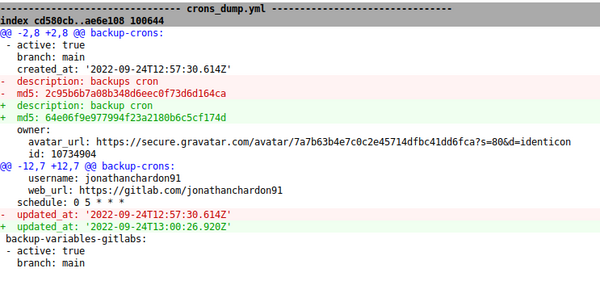
J’ai mis un schedule toutes les heures parce que c’est bien moins critique que les variables d’env et le rythme de changement devrait être bien plus lent. On est maintenant couvert sur ces deux modifs manuelles qui sont plus rapides et bien trop facile à faire pour ne pas se couvrir :) On pourrait faire ça en terraform, mais cela nécessite de la discipline et y’aura toujours quelqu’un pour faire sauter ça.
Parce que:
- ça m’a pris 10 secondes de le faire
- je n’ai pas besoin de connaitre terraform
- j’ai les accès au projet, pourquoi j’irais demander des accès en plus ou modifier un code d’infra compliqué ?
- je n’ai juste pas le temps, mon projet est à la bourre (l’excuse de merde que tout le monde sort)
- j’ai besoin d’autonomie, la personne qui le fait habituellement n’est pas là (promis je lui dirais si je n’ai pas oublié)

Il te faut un moyen serein de gérer les joyeux petits incidents de prod et les esprits un peu trop créatifs :)
versionner la cicd en dehors des repo de code
Le yaml à un défaut majeur, les merges sont compliqués à relire. Quand on mélange du code métier et de la ci/cd, traquer les modifs sans erreurs et sans casser du code est un peu stressant et compliqué. Je conseille de plutôt versionner la CI/CD et les scripts associés dans un repo dédié et de faire des tags de version propre. C’est d’autant plus important quand plusieurs repos utilisent le même fichier yaml.
Il suffira ensuite d’utiliser les includes pour forcer une version spécifique de la CI/CD. https://docs.gitlab.com/ee/ci/yaml/includes.html
Par exemple dans mon projet de code, mon fichier gitlab-ci contiendra ce yaml (J’ai mis la branche main en référence, mais un tag c’est encore plus précis) Ce yaml fait référence au fichier .gitlab-ci.yml dans mon repo cicd_common.
|
|
Plusieurs effets cool de cette méthode:
- versionner et figer une version précise et stable de la ci/cd
- réduire la complexité des merges
- ne pas polluer les repos de code avec des tentatives de modification de yaml
- inclure des tests des scripts utilisés dans la CI/CD
- rollback et changement de la CI/CD maitrisé sur un ou plusieurs repo
- créer des branches de CI/CD totalement divergentes de la version main pour tester et casser des trucs sans impacter directement les devs
- versionner et mutualiser des scripts utilisés dans la CI/CD
Alors quand c’est possible, soit cool, et laisse tes devs en dehors des dramas du yaml game.

Utilisez une image custom gitlab et automatiser sa mise à jour
Dans certain cas, il peut être intéressant de faire un runner dédié avec une image docker custom qui regroupe tous les outils nécessaires dans une seule image. Là ou ça devient vraiment intéressant, c’est de mettre le nom de cette image en variable de groupe et de permettre le changement de cette variable pour toutes les CI/CD du groupe :)
J’aime bien avoir python3 + gcloud + docker dind + tfenv dans la même image. pour builder des containers, lancer des commandes gcloud depuis la CI/CD pusher vers le registry google, lancer du terraform …
Concrètement on fait comme ça:
le dockerFile
|
|
On construit notre image sur docker dind pour nous permettre de faire des actions docker dans le container. Ton runner doit avoir le droit de puller et pusher sur ton repo, le mode privilégier et le binding du socket docker dans le toml du runner pour fonctionner.
|
|
On peut tout à fait builder cette image avec cette même image, mais pour éviter d’être bloqué, ça peut être une bonne idée d’utiliser gcloud builder pour cette image uniquement. Ensuite un petit coup de script python et tu peux mettre à jour ton image dans la variable de group.
|
|
Premier run
|
|
Deuxième run
|
|
Lance ce script en CI/CD dans ton repo avec le dockerfile pour avoir une trace du changement. Ça peut être malin de mettre des tags propres sur les noms des images (hash de commit ou version sémantique v1.1.1 par exemple). Bon je suis d’accord pour dire que les noms de clefs hardcodés ce n’est pas fou, si tu veux un truc un peu plus modulaire, utilise ce bon vieux arg parse. D’ailleurs un truc qu’on faisait dans une ancienne mission (coucou Antoine), c’est qu’on persistait de l’info dans les variables de ci et aussi dans le wiki et le snippet Gitlab.
à toi de voir si tu préfères un runner unique qui tabasse, les runners de gitlab SASS ou les runners en kube.
Un petit kube, un gros kube, c’est l’heure de payer la facture ! ah non ça doit pas être ça la pub :)

backup de la configuration des repos
Dernière astuce, si vous travaillez en terrain miné, il peut être de bon ton de faire des backups de la conf des repos. Surtout si vous avez mis en place des règles restrictives sur le repo et que des admins désactivent ces options de temps en temps. Pour faire du sale ou pour faire une action legit, parfois on n’a pas le choix de passer hors process, mais c’est important de vérifier que les règles soient remises en place une fois la malversation terminée.
On reprend une même base de script et on remix un peu tout ça ! recyclage je vous dis :)
|
|
|
|
On reprend la même base de script, mais cette fois-ci on backup la conf des repo + la conf des protected branche + la conf des protected tags. Comme ça on sait tout de suite si quelqu’un a touché à l’allow push force d’un repo par exemple.
Ça peut faire gagner un temps considérable si on travail en environnement un peu trouble. par exemple des gens qui font des réécritures d’historique git, qui font push force sur master sans trop faire attention au travail des autres. Ou qui joue avec ce genre d’outils :)
https://lesjoiesducode.fr/git-blame-someone-else-blamez-les-autres-pour-votre-mauvais-code-github
https://rtyley.github.io/bfg-repo-cleaner/
On vous voit bandes de margoulins, je n’en ai pas la preuve, mais au moins j’aurai des indices :)

Conclusion
Le python SDK de Gitlab est extrêmement puissant à partir du moment où on prend le temps de jouer un peu avec, ça prend du temps, mais ça vaut le coup. C’est important de versionner et d’automatiser les zones grises de l’infra et de la conf pour éviter de se retrouver au dépourvu devant l’imprévu. Garde le Bash pour les trucs simples et prends Python dès que tu commences à manipuler des API ou des formats de données compliquées.
Je te conseille vivement de potasser la doc du python SDK pour voir tous les trucs super que tu peux faire avec https://python-gitlab.readthedocs.io/en/stable/api-objects.html. Bien sûr si tu commences à avoir masse code qui se ressemble, ça vaut le coup de factoriser tout ça dans une lib pour éviter de trainer une code base avec beaucoup de code dupliqué.
Team serpentard, team des flemmards. (je n’ai pas trouvé une meilleure rime et j’ai la flemme)
