Je restaure des vieux memes
Hello there, General Kenobi

Comme tu le sais surement, je suis un grand fan de memes :)
Aujourd’hui je te propose de faire du déterrage de vieux memes et de tenter de les restaurer avec du machine learning. Pour leur donner l’occasion de briller de mille feux une nouvelle fois et restaurer un peu de leur gloire passée !
On vas s’appuyer sur un outils sous licence S-Lab License 1.0
Je cite Shangchen Zhou, Kelvin C.K. Chan, Chongyi Li, Chen Change Loy bravo à eux :)
https://github.com/sczhou/CodeFormer
Je pourrai utiliser ma tour de jeux avec mon GPU perso, mais j’ai envie de jouer avec les GPU de Google !
J’ai commencé à faire et à écrire beaucoup de bêtises dans cet article basé sur des hypothèses fausses, mais par pédagogie et par honnêteté intellectuelle, j’ai décidé de laisser mon moi du futur corriger mes conneries du passé :) Ce qui va donner un article encore plus décousu et désordonné que d’habitude, la rédaction assume cet effet de style …
Au fur et à mesure du temps j’ai compris que codeformer ne fait pas vraiment de l’upscaling et que ça ne répond pas à mon besoin prétexte de cet article. Je peux dire cependant que mon idée d’architecture est valide, je finirai en fin d’article avec la conclusion qui s’impose.
Considère qu’à chaque fois que tu vois cette couleur, c’est le visiteur du futur qui revient !

N’écris surtout pas cet article, sinon, voilà ce qui va se passer !
Archi Parmentier
A priori on a deux choix pour utiliser des GPU de Google, du kube avec un GPU accroché à un node, ou alors un compute des familles avec un GPU dessus.
J’ai envie de m’abstraire de la complexité et du coût de kube, donc on va faire du compute pour cette fois-ci.
On vas profiter un peu aussi des images google préconstruite avec les drivers préinstallés et tous les prérequis chiants que je n’ai pas envie de gérer.
On va se donner une contrainte un peu sympa, pas de compute allumé pour rien.
On va faire une infra asynchrone avec du cloudrun en frontal pour déclencher notre traitement d’image sur le compute à la demande.
Mon idée c’est d’allumer notre compute à la demande et lui demander bien sagement de s’éteindre une fois les traitements terminés après quelques minutes d’inactivité.
Je te fais un schéma comme si j’étais architecte pour que tu comprennes mieux mon idée !
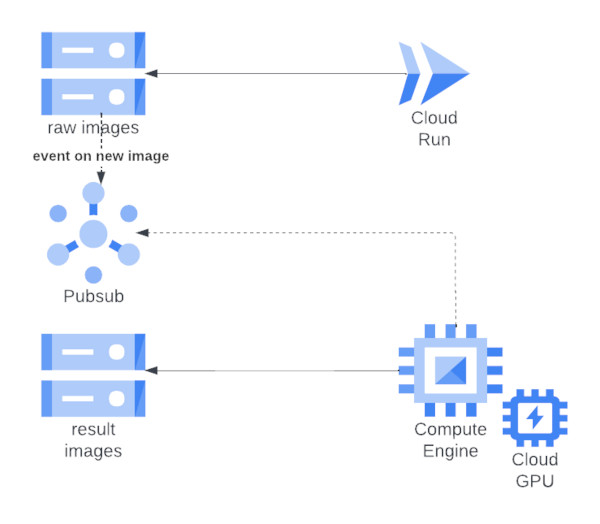
Je me rends compte que rien ne va dans ce schéma, je vous mets la nouvelle version avec un peu plus d’explication !
Je vous laisse ce premier schéma quand même parce qu’il reflète le niveau de flou de mon idée principal. C’est vraiment l’idée embryonnaire la plus brute que j’avais, et c’est intéressant de voir ensuite vers quoi je suis partie.
Je n’avais même pas pris la peine de rédiger des explications, mais mon idée c’était de déclencher la création du compute sur évènement pubsub. Je me suis vite rendu compte que pubsub rajoutaient une complexité inutile et que c’était plus simple que le compute liste lui même les fichiers à consommer.
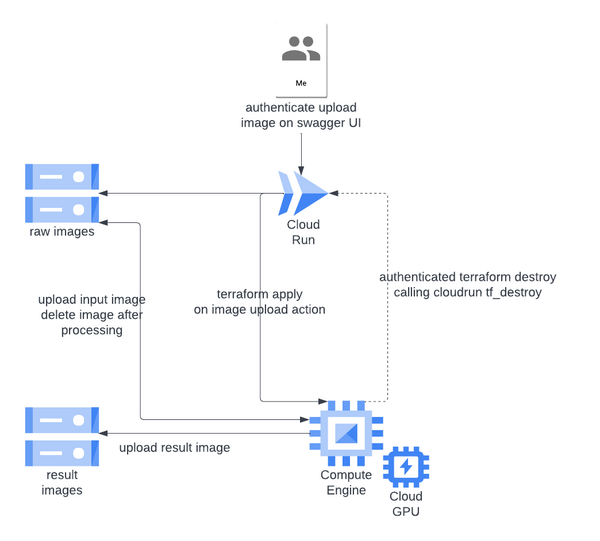
Donc la nouvelle version du diagramme
On enlève pubsub qui est inutile.
l’utilisateur upload des images via cloudrun/fastapi
si cette route reçoit des images dans le bon format:
elle upload les images dans le bucket d'input
elle déclenche un terraform apply dans le cloudrun
Le compute ce lance et démarre directement le daemon de traitement des images
Les images sont téléchargées
le traitement des images est effectué
le résultat est uploadé dans le bucket de résultat
le daemon appel la route tf_destroy sur le cloudrun
le compute est détruit

Premières désillusions
Il faudra augmenter les quotas en faisant une demande à GCP (traité dans les 10 minutes automatiquement en général)
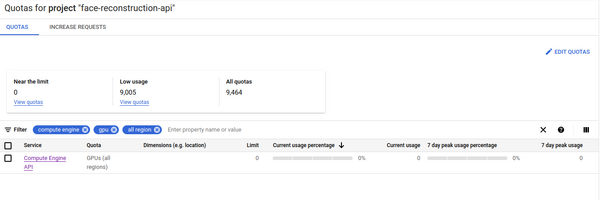
Truc “rigolo” on ne peut pas éteindre les compute avec GPU attaché, qu’à cela ne tienne, on va faire du delete recreate, c’est encore plus radical que d’éteindre et de rallumer le compute et les trucs radicaux, j’aime ça :)
Je suis partie sur ce postulat complètement faux depuis le début, comme j’ai commencé à provisionner avec terraform et des machines peremtible. On peut très bien éteindre et rallumer les machines avec GPU à condition qu’elle ne soit pas peremptible.

Ça m’oblige à faire une image immutable et démarrable le plus rapidement possible, on va faire du packer et blober toute notre logique dans une image.
On va prendre un nvidia T4, c’est le moins cher des GPUs dispo sur GCP et je pense que c’est largement suffisant pour le besoin, 3000 boule l’unité quand même à l’heure ou j’écris (le prix de la carte, pas de la location de la machine) !
pouloulou j’ai choisi un vm avec cuda et tensorflow préinstallé et au premier boot j’ai droit a un truc comme ça
|
|
qu’à cela ne tienne, on vas bourrer toute la merde dans un startup script et se taper toute l’installe à chaque fois :)
La méthode du starter script me faisait des créations de compute plus longue que le traitement des images. Ce n’était pas l’idée du siècle, mais ça m’a permis de valider mon mécanisme et d’ensuite revenir sur packer.
On va faire absolument tout ce qu’il ne faut pas faire en scénario compute normal :
- un startup script de l’enfer
- du apt install en pagailles
- installer les drivers au démarrage
- installer une liste pas possible de lib python
- lancer mon daemon python de traitements d’image
On part sur un handicap massif, dès le début, mais je pense que ça vaut le coup, juste pour le challenge incroyablement stupide et compliqué que ça représente. I get it Google, tu veux rentabiliser tes cartes physiques dans ton datacenter, et me faire payer les grosses thunes pour amortir le matos. Mais je n’ai pas dit mon dernier mot, tu vas voir de quel gaz je ne me chauffe pas cet hiver :)
mais ne t’inquiètes pas mon ami Google, contrairement à mes POCs précédents, tu vas pouvoir prendre un peu d’argent :)
On peut en fait parfaitement faire du packer avec des GPUs, il faut juste un peu plus fouiller et bricoler en dehors de la doc officielle. Cette petite manoeuvre de tout fourrer dans le cloudinit est responsable de la majorité des dépenses de ce projet, donc avec le recul, j'aurai du passer plus de temps sur packer. Donc pardon à Google pour cette mauvaise fois incroyable de la part du jeune joueur français, nuages rouge ! Je te donne mes sous bien volontiers, on ne peut pas gagner à tout les coups !

On fait marcher le script manuellement
Je pars sur un startup script comme ça, on mettra ensuite un daemon python pour nourrir la machine.
|
|
Rien de super intéressant, c’est la doc d’installation de CodeFormer que j’ai fait rentrer au chausse-pied dans un starter script.
- Je créé un user codeformer.
- On installe le driver nvidia, anaconda et les libs de codeformer.
- Il manque basicsr pour télécharger les modèles, c’est pour ça que je l’ajoute à la suite du requirement install.
- On télécharge les données du modèle.
Ce startup script marchouillait en mode semi-auto, mais j’ai du le retravailler ensuite pour le faire rentrer dans packer, et lancer les scripts complètement de manières automatisées. Principaux soucis, anaconda et le sourcing du shell de l’utilisateur codeformer. J’ai essayé plusieurs fois de me passer d’anaconda, mais c’était une purge totale :)

J’ai réussi un premier test
Maintenant qu’on a un premier test manuel qui fonctionne, c’est là que la fête commence :)
Je vous mets ici la première image que j’ai réussi à restaurer !


J’affine ma première idée
Donc c’est super, on à un truc qui fonctionne et maintenant il va falloir mettre en place une logique de construction destruction du compute. On va utiliser terraform et fastapi pour faire ça et rentrer toute la logique dans le même cloudrun. Au moment de l’écriture de ces lignes, j’avais pour idée d’utiliser des cloudfunctions pour apply et destroy terraform. Comme j’ai besoin du binaire de terraform, ça ne rentre pas en fonction, également je trouve plus simple d’embed le code tf directement dans le container pour avoir un blob de l’ensemble. un seul endroit pour apply et destroy mon tf et moins de risque de corruption.
Tout mettre dans le startup script ne ma facilite vraiment pas la vie, j’aurai aimé pouvoir faire mes install dans un packer et embed mon code plus facilement… ça donne un truc un peu moche et pas simple à maintenir et à tester, mais je vais aller au bout de ma démarche et voir ensuite ce qui pourrait s’améliorer !
J’espère que vous avez du PQ sur vous parce que vous allez en chier

Ceci est une référence maintream de 2014
J’ai eu un mal de chien à faire fonctionner la logique cloudrun, fastapi terraform, parce que j’ai voulu tout faire marcher en même temps. Si j’avais été un peu plus ordonné, j’aurais dû être certain à 100% que mon compute GPU fonctionne en terraform avant de commencer à essayer d’apply destroy depuis cloudrun :) J’ai été pressé par le temps et par les coûts, j’aurai du me poser un peu plus et prendre du recul, mais c’est aussi ça les POCs !
je persévère finalement à faire une image packer avec des GPUs
Finalement, je me suis rendu à l’évidence que ma méthode n’était pas bonne. Le startup script au lancement de la machine met plus de temps à s’exécuter à chaque démarrage. Le cloudrun avec le code terraform embed rend le problème encore plus compliqué. Impossible de construire ou de détruire avec un terraform installable
Il m’a fallu du temps pour trouver comment fonctionne packer avec des GPUs, voici comment j’ai finalement résolu mon problème.
Google fournit des images déjà toutes prêtes avec tensorflow et cuda installé. pour les choisir, on peut regarder dans la doc Google:
https://cloud.google.com/deep-learning-vm/docs/images
ou lister les images dispo avec gcloud
|
|
y’en à beaucoup moi j’ai choisi celle-ci
tf-latest-gpu-v20221107-debian-10 debian 10, dernier GPU et tensorflow/cuda
Donc maintenant voici le json que je donne à packer pour faire mon image.
|
|
Les choses auxquelles il faut faire attention:
zone et image_storage_locations: Il faut que l’image finale et que l’image de base soit stockée dans une zone et une région qui héberge des GPUs, dans mon cas j’ai pris europe-west4.
https://github.com/hashicorp/packer/pull/5137/commits/2e1f85a3f2e3f6951de516e0aa421084b4c2e216 Ce bout de machin est le seul indice que j’ai trouvé pour l’explication du setting qui suit
on_host_maintenance: “TERMINATE” les computes avec GPUs ne supporte pas les lives migrations
le lien de l’API technique des GPU, pour obtenir cette information, gcloud vous aidera:
attention à la zone, attention au nom de projet
"accelerator_type": "projects/face-reconstruction-api/zones/europe-west4-a/acceleratorTypes/nvidia-tesla-t4",
"accelerator_count": "1",
|
|
dernier petit “désagrément” à savoir quand on utilise ces images avec packer:
GCP qui active auto-update dans les images de deeplearning, c’est sympa, mais ça m’oblige à mettre un gros sleep sale en début de packer.
Et oui, un gros sleep, parce que sinon aucun moyen d’avoir le release du lock apt, pas de moyen simple à ma connaissance en pur bash de faire une boucle d’attente de release du lock.
OK donc là c’est un peu deep si on connais pas bien apt get, alors je te mets une petite explication.
Plus d’info sur le lock apt
Quand on lance des actions d’installation ou de mise à jour avec le gestionnaire de paquet apt, il met en place un fichier de lock. Le principe c’est de bloquer une deuxième action apt et éviter les corruptions d’installation de package.
Dans mon cas précis, ça m’arrange pas tellement d’avoir un apt lock au moment ou j’essaye d’installer mes dépendances avec packer. je n’ai pas d’outils simples dans la machine pour facilement vérifier si le lock apt est verrouillé ou pas. En gros au moment de mes installations, si le lock est occupé, je ne peux pas installer de binaires pour me permettre de tester si le lock est occupé. Ça fait planter mon packer, et du coût je fais une temporisation de 4 minutes pour attendre la fin des mises à jour automatique déclenchée au démarrage de la machine. packer lance les scripts plus rapidement que cloudinit, c’est pour cette raison que je n’avais pas ce souci en cloudinit.
Connard de tracteur, casse-toi on bosse

Ou lalalala lala Babylone, oh, Babylone
ce qui m’amène aux scripts suivants:
|
|
C’est bête, mais en fait il faut quand même installer le driver nvidia dans le contexte anaconda de codeformer. C’est pour cette raison que le driver est installé dans le second script, mais que initialement j’avais nommé le script driver install .

|
|

Est-ce que tu te souviens de la minicooper dans driver 2 ? non ?
Donc l’astuce c’est de créer un user et de construire un env anaconda en tant que cet user avec toutes les dépendances. Anaconda est particulièrement casse pied dans ce contexte, puisque cloudinit est root sans vrai shell. il faut donc ruser pour utiliser anaconda à l’installation et réutiliser l’env dans un autre script par la suite.
Une fois notre image packer construite, on fait du terraform pour le provisionning et notre daemon python pour automatiser notre routine codeformer. Ça nous donne quelque chose comme ça.
cloudinit.sh
|
|
Anaconda nous oblige à le sourcer et on réactive l’env de codeformer + on installe les dépendances du daemon python qui va gérer notre routine.
|
|
le code python du daemon

|
|
alors ça fait quoi ce machin ?

GracefullKiller, l’idée c’est que si notre process prend un kill, il s’éteint proprement sans faire de vagues.
tant qu'on ne prend pas un kill système
On nettoie un première fois le répertoire d'input de codeformer
On liste les fichiers dans le bucket d'input
si y'a des fichiers
on les downloads et on fait le traitement
sinon
on sort de la boucle
on lance le traitement codeformer
on copie le résultat du traitement
on supprime les images dans le bucket d'input
on appel terraform destroy sur le cloudrun avec un token google sécurisé (le compute à le droit run invoker)
coté terraform ça nous donne un truc comme ça. On note le Base64 encode et décode, ça me permet de m’affranchir des problèmes d’escape string et de formatage de mes scripts. ça me permet un découpage en plusieurs fichiers logiques sans altérer les scripts.
|
|
également, on note les permissions storage admin et run invoker, pour nous permettre de réaliser nos actions sur les buckets et faire les appels authentifiés vers cloudrun. Notre image générée par packer réduit considérablement le temps de run de la machine.

notre code API côté cloudrun
|
|
Rien de bien compliqué finalement là-dedans.
ça mériterait un coup de clean et des tests,
mais comme on est en mode POC rapide, meh ¯\_(ツ)_/¯
Vous allez me dire, pas d’authentification, vérification pauvre, c’est du propre !

Et bien en fait je laisse cloudrun en mode authentification obligatoire et j’appelle ma route avec un cookie headers . Donc c’est dégeux, mais je suis protégé par un token fort de Google. J’ai conscience qu’en entreprise c’est pas bien jojo, mais la y’a que moi sur la subscription. C’est dommage de me taper plein de code pour une authentification alors que je suis tout seul :)
Pour accéder au swagger fastapi, il me suffit de setter un Autorisation header avec le token que j’obtiens depuis gcloud. J’ai une extension firefox qui me permet de faire ça tranquille. Ne pas oublier de l’enlever ensuite, sinon l’UI gcp sera toute chamboulée :)
Conclusion
On en arrive au moment douloureux de faire les comptes. Cette petite blague m’a coûté quelques heures et 50 balles de GCP :)
Je ne regrette rien, j’ai pu valider :
- que c’était possible de provisionner du compute avec Cloudrun
- que les computes avec GPU sont tout aussi packerisable que les computes classique
- que faire un poc en mode arraché à des limites et que parfois il faut prendre du recul
- que même avec une idée et un schéma flou, on peut réaliser de belle chose
C’est intéressant d’un point de vue économique de pouvoir éteindre les machines quand on ne les utilise plus. Un équivalent en kube ça serait d’allumer et d’éteindre les nœuds à la demande. C’est quand même bien plus compliqué que de faire des containers.
Je savais que j’aurai du faire du kube, mais voilàààà, mais c’était sur en fait !
