ESSAI: Kubernetes n'est pas Borg
Hello les amis, Je voudrais prendre un peu de temps pour décortiquer l’article de recherche Large-Scale Cluster Management at Google with Borg de Google Research.
Je sais que ça a déjà été fait par le passé. D’ailleurs, voici une version actualisée qui parle de Borg, Omega et Kubernetes (source : LinkedIn, Yashar Esmaildokht). Mais j’aimerais y rajouter mon interprétation personnelle, un maximum de mauvaise foi, des analogies tirées de mon expérience personnelle et ma petite patte de punk à chien, bien entendu :)
Ma motivation principale, c’est de rendre ce contenu un peu moins formel et académique, tout en vous faisant réfléchir sur les pratiques et usages du cloud de Google. J’irais bien remuer la marmite à étrons des autres cloud providers, mais je ne connais pas de document académique sur les méthodes et outils internes du cloud de tonton Bezos ou de celui de Microsoft.
Ceci étant dit, on part dans les méandres fonctionnel de Borg. Tout le monde à bord du train fantôme, on part chatouiller un peu le Boogeyman sur les terres de Google.

C’est quoi Borg ?
Borg est un orchestrateur de charges de travail en cluster à une très grande échelle (allant jusqu’à des dizaines de milliers de machines).
Google’s Borg system is a cluster manager that runs hundreds of thousands of jobs, from many thousands of different applications, across a number of clusters each with up to tens of thousands of machines.source : Large-Scale Cluster Management at Google with Borg
Ce n’est pas un système d’exploitation, ni un hyperviseur de datacenter. L’hyperviseur de Google est un KMV durci.
Le système d’exploitation n’est pas divulgué publiquement, mais il s’agit probablement d’un OS basé sur Linux, modifié pour réduire la surface d’attaque. La seule certitude, c’est que GCP n’utilise pas QEMU et contrôle très précisément le code de KVM ainsi que celui de son hôte pour durcir la sécurité sans compromis.
Code Provenance: We run a custom binary and configuration verification system that was developed and integrated with our development processes to track what source code is running in KVM, how it was built, how it was configured and how it was deployed. We verify code integrity on every level from the boot-loader, to KVM, to the customers’ guest VMs.
Cette gestion bas niveau de l’infrastructure permet à Google de maîtriser pleinement les coûts et la sécurité de ses datacenters, tout en leur assurant une indépendance technique vis-à-vis des fournisseurs d’hyperviseurs comme VMware. Cela ne les empêche pas de fournir également un service managé Google Cloud VMware Engine (GCVE), pour les clients qui veulent un environnement VMware sur GCP, ainsi qu’une solution Google Cloud Bare Metal Solution (BMS) pour les charges de travail spécifiques nécessitant un accès direct au matériel physique. Parfait pour les petits malins qui veulent coller leurs gros serveurs Oracle dans GCP ou faire tourner Gentoo, hihihi. (Personnellement, je ne comprends pas trop l’attachement à faire du cloud ET du bare metal, mais bon.)
On comprend facilement que chez Google (sauf cas spéciaux), les conteneurs passent en premier, et, au pire, on utilise des VMs légères. Pour finir de s’en convaincre, le premier service de charge de travail commercial de Google était App Engine en 2008, dans une démarche serverless. Compute Engine est arrivé plus tard, en 2O12.
Borg couvre donc l’ensemble des charges de travaille aussi bien en VM légère que en container.
Maintenant ce qui nous intéresse dans cette histoire c’est que Kubernetes est dérivé de Borg et que le papier de recherche détaille fonctionnellement Borg et permet de le comparer avec Kubernetes.
Architecture technique Borg et Kubernetes
Les gens déjà familiers avec le fonctionnement interne de Kubernetes ne seront pas trop dépaysés par le fonctionnement de Borg. C’est sensiblement la même architecture, avec quelques spécificités propres à Google.
On va quand même passer un peu de temps à la redéfinir, l’expliquer et la comparer avec Kubernetes.
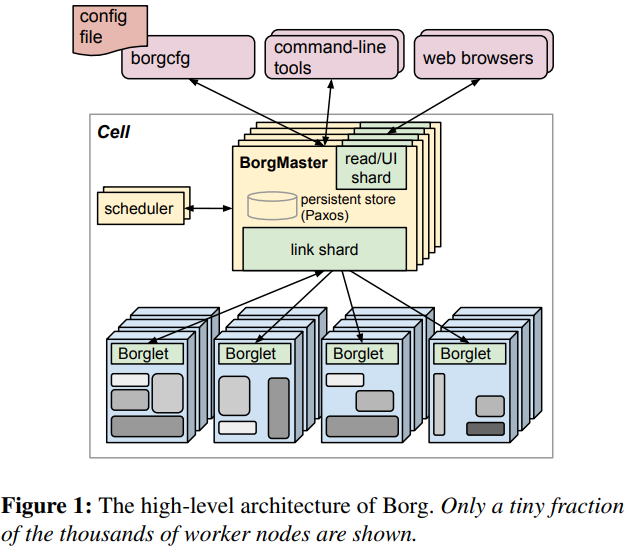
Borg fonctionne sur une architecture distribuée organisée autour du Borg Master, qui est la brique principale de contrôle du cluster. Il est associé à son scheduler, qui permet de recevoir les ordres et de placer les charges de travail dans le cluster. Les données du Borg Master sont stockées dans une base clé-valeur persistante (non nommée dans le document) basée sur le protocole Paxos.
Le Borg Master reçoit des directives de déploiement de workloads. La brique scheduler est chargée de décider de la position des workloads sur le cluster. Un agent Borglet sur les workers est chargé de lancer les conteneurs et d’assurer leur intégrité en fonction des besoins soulevés par le Borg Master.
Un cluster Borg (qui rassemble les masters et les nœuds) est appelé une cellule (“cell” en anglais) et est capable de fonctionner avec des workloads hétérogènes.
Borg est construit pour avoir une architecture redondante et tolérante aux pannes, permettant de déplacer les charges de travail en cas de défaillance matérielle.
GCP est capable de planifier des live migrations en situation de maintenance planifiée afin de réduire au maximum les indisponibilités de service.
Maintenant si on compare avec l’architecture de kubernetes
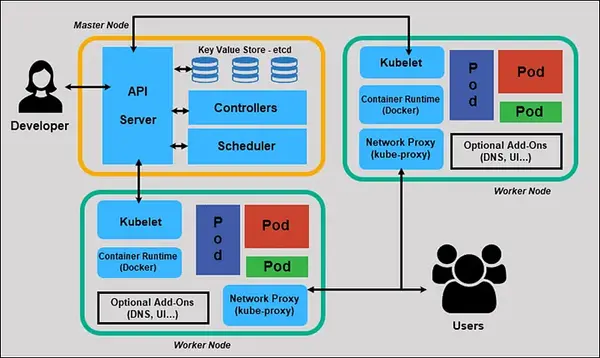
On retrouve les mêmes concepts, mais avec des noms différents. Là où le Borg Master est plus monolithique, Kubernetes découpe le plan de contrôle en plusieurs composants :
- API Server : permet la communication avec le master node et les différentes briques distribuées du master (envoi des directives de contrôle).
- ETCD : assure le stockage persistant, en remplacement du stockage interne de Google dans Borg.
- Scheduler : décide sur quel nœud exécuter les conteneurs.
- Contrôleurs : s’assurent que l’état désiré du cluster est appliqué.
- Côté worker nodes, on retrouve Borglet renommé en Kubelet, qui fait la même chose, et Kube-Proxy, qui gère les tâches réseau.
En résumé, c’est la même chose … mais en moins bien !
Maintenant que j’ai balancé mon pavé je vais détailler mon affirmation !
Long-running services et batch jobs
Borg est capable de distinguer la mise en place de service en continu qui ne doivent jamais tomber en panne et qui tourne pendant longtemps. Utilisé pour des produits comme Gmail ou google Drive, grand public et les service comme bigtable (service managé GCP).
Le second type de service sont les batch jobs, qui peuvent prendre entre quelques secondes et plusieurs jours à s’éxecuter.
Borg est capable de mixer ces charges et équilibrer les ressources au plus juste pour limiter la baisse de performance.
Le premier type de scheduling est ce qui vas faire la différence entre un service managé CloudSQL performant et résilient et un container postgresql mal branlé, fourré dans un kubernetes avec un pied de biche, oui kubernetes peux gérer des charges stateful, mais a quel prix ensuite .
Borg manage bien plus efficacement les services en temps long et sa capacité à managé aussi bien des micro vm que des containers permet d’avoir une stabilité et une flexibilité inégalé sur les service stateful au temps long, comme les bases de données. Plus l’expertise de Google et l’échelle à laquelle les services sont déployer et tester en interne serons toujours meilleurs quie le helm que vous avez trouvez sur le net.
la capacité à prioriser et hierachiser la priorité des tâches rend Borg plus précis et puissant pour gérer des taches sensibles haute performances.
L’ordre de grandeur démentiel
un cluster borg correspond en moyenne à 10.000 machines regroupé dans un bâtiment et un ensemble de batiment regroupe un site (un site peux correspondre à une zone géographique du cloud).
The machines in a cell belong to a single cluster, defined by the high-performance datacenter-scale network fabric that connects them. A cluster lives inside a single datacenter building, and a collection of buildings makes up a site.1 A cluster usually hosts one large cell and may have a few smaller-scale test or special-purpose cells. We assiduously avoid any single point of failure. Our median cell size is about 10 k machines after exclud- ing test cells; some are much larger.source : Large-Scale Cluster Management at Google with Borg
Par comparaison un cluster kubernetes est bien plus limité en terme de quantité de worker et de pods qu’il peut géré. (bon 5000 nodes c’est quand même honorable).

No more than 110 pods per node No more than 5,000 nodes No more than 150,000 total pods No more than 300,000 total containers You can scale your cluster by adding or removing nodes. The way you do this depends on how your cluster is deployed.
https://kubernetes.io/docs/setup/best-practices/cluster-large/
On comprend facilement que au vu des exigences et des contraintes de Google, Borg est bien plus solide et adapté à leur besoin, l’ordre de grandeur n’est juste pas comparable.
La gestion des priorités des charges de travail
Borg peut gérer finement les priorités et les quotas, avec la capacité de rendre certaines charges de travail préemptibles (c’est-à-dire qu’elles peuvent être supprimées et replanifiées si les ressources viennent à manquer).
Borg peut aussi réserver des ressources (allocs) pour équilibrer la demande et créer des “placeholders” de ressources qui peuvent être libérés si nécessaire.
Certaines tâches peuvent être déplacées si une augmentation des ressources est requise sur un nœud qui ne dispose pas des ressources nécessaires.
Borg à plus de garantie de disponibilité de ressource grace au allocs qui lui permet de placer les ressources avec les ressources réels, la ou kubernetes permets l’overprovisionning et une plus forte densité pour moins de ressources via les ressources limit et requests. Kubernetes est plus flexible, mais pour google la prévisibilité est plus importante et Borg apporte plus de garantie sur ce point.
L’objectif principale de Google est d’optimisé au maximum l’utilisation des ressources, sans compromis sur la disponibilité de 99.9%.

La gestion des VM avec borgs
Comme dit précèdement, borg est capable de scheduler des vm directement sur l’hyperviseur de KVM comme des taches Borgs classique, les VMs computes engines sont donc traité comme des taches Borg classique.
L’accès SSH est restreint via borgssh, qui limite les connexions aux tâches spécifiques d’un utilisateur.
En comparaison, si on devait faire la même chose avec Kubernetes, on pourrait utiliser KubeVirt, qui permet de lancer des VM KVM sur les nœuds Kubernetes. Cependant, on ne pourrait pas avoir la même qualité de service, puisque les VMs seraient installées sur les nœuds du cluster. C’est un peu galère si les nœuds sont eux-mêmes des VMs, car il faut les migrer lors des mises à jour de Kubernetes.
À partir du moment où on comprend ça, GKE est déjà une solution perdante en termes d’efficacité énergétique, de ressources consommées et de disponibilité des services.
Je vous ai parlé de Cloud Run ? Non ? Faites du Cloud Run les amis, c’est bon pour la santé !

Knative et Cloud Run sont fortement liés
Bon Puisque vous insistez, je vais vous parler de Cloudrun :) On dit du mal de Kube précédement, mais Knative s’appuis sur Kubernetes pour déployer des charge serverless et ça tombe bien, parceque Cloudrun s’appuit sur Knative.
Du coup on peux en déduire que Cloudrun permet de lancer des containers en mode serverless, et ainsi supprimer la complexité de GKE et la consommation de ressources, tout en aillant un service plus simple à mettre en place et qui scale sans efforts.
Du coup, GKE caché derrière en temps que couche d’abstraction ? Toujours Borg/meteor adapté ou plus ou moins étendu par Knative ? Sauce secrète de GCP :)
ici quelqu’un qui à comparé les deux
et GKE / GKE autopilot ?
Là où on rentre dans les trucs rigolos, c’est quand on pense à GKE et à GKE Autopilot.
À chaque nouveau cluster, Borg planifie des machines pour faire tourner le cluster GKE, le contrôle plane et les nœuds.
C’est du ClusterCeption, un outil d’orchestration qui orchestre un orchestrateur et avec autopilot on abstrait la gestion de ces nœuds pour masquer sa complexité !
Du coup, on revient au bon vieux débat : est-ce que mon projet vaut le coût et l’énergie d’investir dans Kubernetes, en autopilot ou en GKE standard ? Mon cluster va me bouffer une quantité de ressources incompressible et m’apporter une complexité de gestion, avec l’ajout de toujours plus de pods pour ajouter des fonctionnalités. Il faut vraiment que le projet vaille le coup pour s’infliger une contrainte pareil.
Conclusion
Je pense ne pas avoir dit trop de conneries sur le fonctionnement de Borg, et j’espère vous avoir appris des choses intéressantes sur GCP et son écosystème. J’espère ne pas avoir froissé les fanboys et fangirls de Kubernetes, et je vous dis à la prochaine pour un nouvel article !
