Hello les amis,
chez mon client actuel, on commence à avoir quelques conteneurs qui tournent sur Kubernetes (avec l’ambition d’en mettre de plus en plus), et l’ami SCC (Security Command Center) nous trouve des CVEs qui s’empilent comme du sédiment, jusqu’à créer du pétrole de vulnérabilité.
J’avoue que la première phrase de l’article pique un peu, alors je vous mets quelques infos pour comprendre où je veux en venir.
Plus d’infos sur Security Command Center
Security Command Center permet aux opérations de sécurité (SOC), aux spécialistes des vulnérabilités et des stratégies, ainsi qu’à d’autres professionnels de la sécurité d’évaluer, d’analyser et de répondre aux problèmes de sécurité dans les environnements cloud.
Pour faire simple, c’est un outil payant qui centralise les remontées de risques de sécurité.
Plus d’infos sur les CVEs
Common Vulnerabilities and Exposures, ou CVE, est un dictionnaire des informations publiques relatives aux vulnérabilités de sécurité.
Ce dictionnaire est maintenu par l’organisme MITRE, soutenu par le département de la Sécurité intérieure des États-Unis.
Pour faire simple, c’est une liste de vulnérabilités connues et documentées publiquement.
Plus d’infos sur la création du pétrole
Le pétrole résulte de la dégradation thermique de matières organiques contenues dans certaines roches : les roches-mères. Ce sont des restes fossilisés de végétaux aquatiques ou terrestres, de bactéries et d’animaux microscopiques s’accumulant au fond des océans, des lacs ou dans les deltas.
Donc, quand je dis que ça s’empile comme du sédiment jusqu’à créer du pétrole de vulnérabilité, il faut comprendre qu’on laisse bien moisir les vulnérabilités et qu’on attend bien longtemps avant de s’en préoccuper.
La posture chez GCP pour éviter les vulnérabilités dans les conteneurs, c’est de maîtriser 100 % de la construction des conteneurs en partant de leurs images de base, maintenues et mises à jour par les équipes de GCP. En principe, cela garantit le moins de vulnérabilités possible.
Documentation sur les images de base de GCP
C’est bien joli, mais si ton équipe ne sait pas construire correctement des images ou utilise des images issues de dépôts communautaires avec des outils déjà packagés, tu crois qu’ils auront envie de refaire une image complète à partir des images de base de GCP ? Ah, la flemme, toi-même tu sais !
Avec des devs de bonne volonté, tu peux espérer des patchs manuels de temps en temps, mais à grande échelle, c’est compliqué de suivre.
Tu peux avoir des devs bon élèves qui mettent à jour leurs images au moment du build, mais si ta fréquence de déploiement est beaucoup moins élevée que la fréquence de publication des patchs pour les CVEs, mécaniquement, de nouvelles CVEs vont apparaître au fur et à mesure que le temps passe.
Le temps est l’ennemi ultime. Il emporte avec lui les bonnes volontés et l’espoir d’un run de prod sans accidents de sécurité.
Et si on prenait le problème dans l’autre sens ?
Au fond, si on prend le problème dans l’autre sens, on a un alerting qui inonde de vulnérabilités et très peu de chances de traiter les vulnérabilités avec réactivité.
Faire un channel d’alerting des findings de SCC ne sera d’aucun secours. Je l’ai fait, et en vérité, il a très vite été décommissionné.
Deuxième idée : faire une spreadsheet qui s’auto-update avec les CVEs remontées par SCC pour rendre les vulnérabilités visibles. J’ai fait ça aussi. On regarde un peu les premières semaines, mais quelques semaines plus tard, tout le monde s’en fiche.
J’ai essayé de patcher manuellement quelques images, et franchement, c’est compliqué.
Ce que j’ai pu analyser des CVEs les plus courantes, c’est que les binaires en C bas niveau, que tout le monde utilise, sont les plus touchés.
Souvent des problèmes de buffer overflow sur des libs comme OpenSSL, cURL et consorts, qui sont incontournables dans l’écosystème Linux.
Ce n’est pas une option de désinstaller ces libs, et il faut utiliser les channels de repo testing pour avoir les versions patchées.
Pas ouf d’installer des versions instables dans un contexte de compute, mais dans un conteneur, avec une capacité de rollback quasi instantanée, ça semble être un risque un peu plus contrôlable.
Il faudrait presque patcher la CVE au moment où elle arrive pour espérer une réduction significative des remontées. Avec une escalade et des requalifications de sévérité, une CVE peut se déclencher plusieurs fois sur la même version.
Du coup, est-ce que je serais assez fou pour faire un système de patching d’image au moment où elles arrivent dans SCC ? La réponse est OUI, Bien sur que OUI.

Concept, schéma, architecture et enclos aux cochons
Ma première idée, c’était d’utiliser copacetic, un petit tool rigolo qui, sur le papier, est capable de patcher les images sans rebuilder, en mettant à jour exactement la version de la lib qui contient le patch de résolution de la CVE. Juste pour vous dire à quel point j’y croyais, c’est cet outil qui m’avait inspiré cette idée.
En combinaison avec un outil capable de scanner les conteneurs et de faire un rapport de vulnérabilité, j’ai nommé l’ami Trivy..
L’intérêt de cette combinaison, c’est que copacetic est capable de patcher les vulnérabilités en se basant sur le rapport de trivy. Sur le papier, ça fait une Starsky et Hutch, puisque les deux outils s’intègrent parfaitement et copacetic est capable de builder et pousser la nouvelle image directement dans le repo cible (ou un autre repo de mon choix).
Petite précision, mais qui a toute son importance : trivy me permet de filtrer les libs systèmes des libs de code.
Je veux absolument éviter de péter le code, et je laisse cette responsabilité aux devs. Par contre, les libs systèmes, aucune pitié.
OpenSSL et cURL avant d’avoir des breaking changes majeurs, je peux me coucher très tôt. Par contre, 2 semaines sans CVEs, c’est une autre paire de manches.

Du coup, c’était sympa, mais la réalité du terrain, c’est que copacetic n’est pas en mesure de gérer certains cas un peu rigolos :
- La version patchée n’existe pas dans le repo stable.
- L’utilisateur dans le conteneur n’est pas root.
- La dépendance nécessite de mettre à jour les libs C liées (copacetic est un fonctionnaire, il ne patch que les libs dans le rapport copacetic).
Donc moi, ça m’énerve, parce que j’ai une somme d’images avec des OS hétérogènes : Debian/Ubuntu/Alpine, parfois j’ai apt, parfois c’est apk.
Vous sentez ce délicat fumet ? On s’approche de l’enclos des cochons, et ce n’est pas l’odeur du napalm au petit matin !
Et oui, Trivy/copacetic, c’était élégant, c’était simple, mais on repart encore sur une technique de nettoyeur de tranchées en 14/18.
On va tailler dans le gras, et on n’oublie pas le gaz moutarde pour l’assaisonnement.

Donc l’idée, c’est qu’on va conserver quand même Trivy, parce que le rapport au format JSON, c’est quand même bien pratique.
Par contre, on va changer de tactique et faire une mécanique bien plus bourrine avec des commandes buildah,,
qui est capable d’ajouter des layers Docker à une image existante, devenir root et conserver quand même l’état du conteneur, les variables d’env, l’utilisateur de base, les métadonnées.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
trivy remonte les CVE et l'OS du container
on fait un dictionnaire unique des CVE existantes
si ubuntu/debian, commande apt, si alpine, commande apk
on devient root
on fait update et upgrade
on relance trivy
si il retrouve encore des vulns
on met les repo test
on fait update
on upgrade seulement les repo avec des vulns restantes
on incrémente le nom de l'image si elle a déjà été patchée
|
C’est bourrin, c’est imparfait, mais en utilisant apt et apk, on est certain que les libs liées sont à jour.
On installe les libs testing seulement sur les libs vulnérables, et comme on sait que ce sont souvent des libs C, qui sont relativement stables en termes de fonctionnalités dans le temps, le risque de casse est limité.
On laisse les devs mettre à jour eux-mêmes les libs de code, qui ont plus de chances d’introduire des breaking changes.
Détails d’implémentation
Maintenant, je vais rentrer un peu plus dans les détails d’implémentation de ma solution.
Je voulais une solution serverless, pour éviter au maximum de cramer du CPU pour rien, puisque 99% du temps le service n’aurait pas été appelé.
Un patch de conteneur dure au maximum 10 minutes, c’est donc une charge hyper volatile et sporadique.
Comme je n’ai pas réussi à me passer du socket Docker pour Buildah et que Cloud Run ne me permet pas de faire du Docker dans le conteneur,
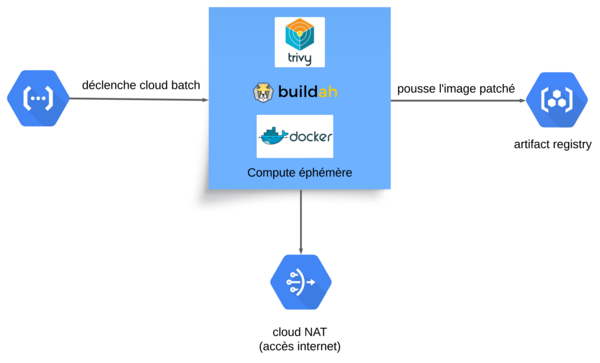
j’ai choisi d’utiliser Cloud Run comme une sorte de proxy de requêtes qui va déclencher un Cloud Batch responsable du traitement.
Plus d’info sur Cloud Batch
Service par lot entièrement géré permettant de planifier, mettre en file d’attente et exécuter des jobs par lot sur l’infrastructure de Google.
La bonne traduction française dégueu du site officiel de GCP :
En gros, c’est un système de batch managé, qui utilise des Compute Engine pour lancer des tâches, soit en mode script, soit en conteneurs.
Ça nous donne SCC qui écrit dans Pub/Sub, Pub/Sub qui est lu par Cloud Run, Cloud Run qui déclenche Cloud Batch.
Dans Cloud Batch, on récupère l’image Docker, on scanne les vulnérabilités avec Trivy, on patch avec Buildah, Docker push, et c’est fini.
Dans la configuration du batch, on rend disponible le socket Docker, pour pouvoir faire du Docker dans Docker.
Et dans mon conteneur de build, on y met Docker Buildx, Buildah, Trivy et gcloud.
Dernières frictions, mais pas des moindres : on ne peut pas auto-déployer les images sans les tester en amont et faire valider la non-régression par les devs.
Bon, ça c’est plus un problème humain qu’un problème tech, donc on va dire qu’on s’en fout dans le contexte de cet article, meh !
Il est frais, mon poisson, il est frais !
C’est avec un peu de déception et d’incompréhension, je dois le dire, que cette initiative n’a pas été suivie par mon client, qui a décidé de mettre ce projet au second plan.
Dommage pour lui, comme je considère officiellement le projet abandonné, je n’ai aucun mal à le proposer dans une version plus légère ici, avec son accord.
Comme je n’ai pas de charge de travail sur GKE ni de SCC activé sur mon orga de lab, je vais réduire mon code au minimum et utiliser une Cloud Function qui prend en paramètre une image Docker. Cette fonction déclenchera un Cloud Batch, patchera l’image et poussera l’image de base et l’image patchée dans un Artifact Registry (pour visuellement plus facilement voir les vulns présentes).
En somme, tout pareil que si j’avais un outil qui me remontait mes images vulnérables.
Donc ça commence dans un premier temps par une image Docker qui servira de base pour ma machine de patch.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
FROM google/cloud-sdk:latest
RUN apt-get update && apt-get upgrade -y && \
apt-get install -y wget tar buildah && \
apt-get clean && rm -rf /var/lib/apt/lists/*
ENV DOCKER_BUILDKIT=1
ENV BUILDKIT_PROGRESS=plain
ENV DOCKER_CLI_EXPERIMENTAL=enabled
ENV STORAGE_DRIVER=vfs
ARG BUILDX_URL=https://github.com/docker/buildx/releases/download/v0.4.2/buildx-v0.4.2.linux-amd64
RUN mkdir -p $HOME/.docker/cli-plugins && \
wget -O $HOME/.docker/cli-plugins/docker-buildx $BUILDX_URL && \
chmod a+x $HOME/.docker/cli-plugins/docker-buildx
RUN wget https://github.com/aquasecurity/trivy/releases/download/v0.51.2/trivy_0.51.2_Linux-64bit.deb && \
dpkg -i trivy_0.51.2_Linux-64bit.deb && \
rm trivy_0.51.2_Linux-64bit.deb
COPY requirements.txt .
RUN pip3 install -r requirements.txt
COPY ./patch-image.py .
|
Dans les trucs un peu subtils, on a besoin de buildx et de VFS pour que buildah arrête de chouiner et puisse fonctionner dans le contexte du container.
J’attrape directement le .deb de trivy depuis le repo GitHub officiel (j’aurais pu mettre le repo source, mais un peu la flemme).
Mon fichier patch_image.py contiendra mon script de colle pour faire fonctionner les briques entre elles.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
|
#!/usr/bin/env python3
import os
import subprocess
import pprint
import sys
import json
from json import dumps
import requests
def run_command(command):
"""
general propose function use to run system command
expected argument command
print on shell stdout and stderr
return status code
"""
print(f"run: {command}")
try:
with subprocess.Popen(
command,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True,
) as process:
for line in iter(process.stdout.readline, ""):
print(line.strip())
for line in iter(process.stderr.readline, ""):
print(line.strip())
process.wait()
exit_code = process.returncode
print(f"Command finished with exit code: {exit_code}")
except Exception as e:
print(f"Error running command: {str(e)}")
exit_code = 255
return exit_code
def check_if_image_exist_and_increment_until_new_image_name(docker_vars):
# if docker manifest return 1, image not exist, so we can use this tag for the patched image
image_not_exist = 0
while True:
image_not_exist = run_command(
f"docker manifest inspect {docker_vars['target_docker_image']}"
)
if image_not_exist != 0:
break
# iterate tag if image exist on remote repository
print(
f"image {docker_vars['target_docker_image']} already exist, incrementing the patched tag"
)
docker_vars = set_target_image_new_tag(docker_vars)
return docker_vars
def set_target_image_new_tag(docker_vars):
# iterate tag if tag from original image is already patched
# check if image exist and iterate tag if image exist on remote repo
if "patched" in docker_vars["original_tag"] or docker_vars.get("new_tag"):
print("image is already tag with '-patched', iterate tag.")
tag_digit = docker_vars["original_tag"].split("-patched-")
if docker_vars.get("new_tag"):
digit = docker_vars["new_tag"].split("-patched-")
if len(digit) > 1 and digit[1].isdigit():
new_patch_num = int(digit[1]) + 1
else:
new_patch_num = 1
if not "-patched-" in docker_vars["new_tag"]:
# this case is only on first tag -patched to prevent -patched-patched-1 numerotation
docker_vars["new_tag"] = f"{digit[0]}-{new_patch_num}"
else:
docker_vars["new_tag"] = f"{digit[0]}-patched-{new_patch_num}"
else:
docker_vars["new_tag"] = f"{docker_vars['original_tag']}-patched"
docker_vars["target_docker_image"] = (
"/".join(docker_vars["current_docker_image"].split("/")[:-1])
+ "/"
+ docker_vars.get("new_tag")
)
docker_vars = check_if_image_exist_and_increment_until_new_image_name(docker_vars)
return docker_vars
def parse_docker_image_vars(docker_vars):
docker_vars["original_docker_image"] = os.getenv("ORIGINAL_DOCKER_IMAGE")
docker_vars["current_docker_image"] = docker_vars["original_docker_image"]
if "/" in docker_vars["original_docker_image"]:
docker_vars["original_tag"] = docker_vars["original_docker_image"].split("/")[-1]
else:
docker_vars["original_tag"] = docker_vars["original_docker_image"]
return docker_vars
def push_image_to_repo_if_target_repo_set(docker_vars):
# if the variable TARGET_REPO is set, the docker image and the patched image
# will be push on this repository
# else the patched image will be sent to the same repo as original image
target_repo = os.getenv("TARGET_REPO")
if target_repo:
authenticate_to_gcp_registry()
print(f"env TARGET_REPO set, push image to repo {target_repo}")
rewrite_original_docker_image = (
f"{target_repo}/{docker_vars.get('original_tag')}"
)
print("image is on a gcp registry, running gcloud set projet on this projet.")
remote_project_name = os.getenv("BATCH_PROJECT_NAME")
if remote_project_name and "/" in remote_project_name:
remote_project_name = remote_project_name.split("/")[1]
gcp_set_project(remote_project_name)
run_command(f"docker pull {docker_vars.get('original_docker_image')}")
run_command(
f"docker tag {docker_vars.get('original_docker_image')} {rewrite_original_docker_image}"
)
target_project_name = target_repo.split("/")[1]
gcp_set_project(target_project_name)
run_command("docker images")
run_command(f"docker push {rewrite_original_docker_image}")
docker_vars["current_docker_image"] = rewrite_original_docker_image
return docker_vars
def gcp_set_project(project):
run_command(f"gcloud config set project {project}")
def authenticate_to_gcp_registry():
run_command("gcloud auth configure-docker europe-west9-docker.pkg.dev --quiet")
def run_trivy_scan(docker_vars):
docker_vars["trivy_result_json_file"] = f"{docker_vars.get('new_tag')}.json"
run_command(
f"trivy image --vuln-type os --ignore-unfixed -f json -o {docker_vars.get('trivy_result_json_file')} {docker_vars.get('current_docker_image')}"
)
def read_trivy_file(docker_vars):
with open(docker_vars.get("trivy_result_json_file")) as file:
trivy_report = json.loads(file.read())
return trivy_report
def extract_trivy_report(trivy_extract, trivy_report):
trivy_extract["os_family"] = (
trivy_report.get("Metadata", {}).get("OS", {}).get("Family")
)
try:
trivy_extract["vulns_list"] = trivy_report["Results"][0]["Vulnerabilities"]
except KeyError:
trivy_extract["vulns_list"] = []
print("no vuln found.")
trivy_extract["uniq_vulns"] = list(
set([vuln.get("PkgName") for vuln in trivy_extract.get("vulns_list", [])])
)
return trivy_extract
def manage_alpine_buildah_update(container_name, trivy_extract):
print("Found Alpine OS")
run_command(
f"buildah run --user=root --isolation=chroot {container_name} -- apk update"
)
run_command(
f"buildah run --user=root --isolation=chroot {container_name} apk upgrade --update-cache --available"
)
run_command(
f"buildah run --user=root --isolation=chroot {container_name} /bin/sh -c \"echo '@edge https://dl-cdn.alpinelinux.org/alpine/edge/main' >> /etc/apk/repositories\""
)
run_command(
f"buildah run --user=root --isolation=chroot {container_name} -- apk update"
)
for vuln in trivy_extract.get("uniq_vulns"):
run_command(
f"buildah run --user=root --isolation=chroot {container_name} apk add {vuln}@edge"
)
def manage_debian_based_os_buildah_update(container_name, trivy_extract):
run_command(
f"buildah run --user=root --isolation=chroot {container_name} -- apt update"
)
run_command(
f"buildah run --user=root --isolation=chroot {container_name} -- apt upgrade -y"
)
run_command(
f"buildah run --user=root --isolation=chroot {container_name} /bin/sh -c \"echo 'deb http://deb.debian.org/debian testing main' >> /etc/apt/sources.list.d/testing.list\""
)
run_command(
f"buildah run --user=root --isolation=chroot {container_name} /bin/sh -c \"echo 'Package: *\nPin: release a=testing\nPin-Priority: 100\n' > /etc/apt/preferences.d/pinning\""
)
run_command(
f"buildah run --user=root --isolation=chroot {container_name} -- apt update"
)
for vuln in trivy_extract.get("uniq_vulns"):
run_command(
f"buildah run --user=root --isolation=chroot {container_name} apt-get install -t testing -y {vuln}"
)
def buildah_commit_push_clean(container_name, docker_vars):
run_command(
f"buildah commit {container_name} {docker_vars.get('target_docker_image')}"
)
run_command(
f"buildah push {docker_vars.get('target_docker_image')} {docker_vars.get('target_docker_image')}"
)
run_command(f"buildah rm {container_name}")
def update_upgrade_container(docker_vars):
print("parsing trivy report.")
trivy_extract = {}
trivy_report = read_trivy_file(docker_vars)
trivy_extract = extract_trivy_report(trivy_extract, trivy_report)
container_name = "update-container"
run_command(f"buildah rm {container_name} || true")
run_command(
f"buildah --name {container_name} from {docker_vars.get('current_docker_image')}"
)
if not trivy_extract.get("os_family"):
print ("OS not found in trivy report, exiting script.")
sys.exit(-1)
if trivy_extract.get("os_family") and "alpine" in trivy_extract.get("os_family"):
manage_alpine_buildah_update(container_name, trivy_extract)
elif any(
family == trivy_extract.get("os_family") for family in ["debian", "ubuntu"]
):
manage_debian_based_os_buildah_update(container_name, trivy_extract)
else:
print(
f"OS family {trivy_extract.get('os_family')} not supported for automatic updates"
)
message = f"update failed, unsupported OS {trivy_extract.get('os_family')}"
send_message_to_google_chat(message)
sys.exit(-1)
buildah_commit_push_clean(container_name, docker_vars)
def main():
docker_vars = {}
docker_vars = parse_docker_image_vars(docker_vars)
docker_vars = push_image_to_repo_if_target_repo_set(docker_vars)
docker_vars = set_target_image_new_tag(docker_vars)
authenticate_to_gcp_registry()
run_trivy_scan(docker_vars)
update_upgrade_container(docker_vars)
if __name__ == "__main__":
main()
|
Donc, on a un script qui fait la liaison entre trivy, buildah, le parsing des libs vulnérables, le patching des vulns en testing en fonction de la lib, l’incrément de l’image si l’image a déjà été patchée les fois précédentes.
Maintenant qu’on a un container avec notre logique de patch, il faut faire le code d’infra pour mettre tout ça en musique.
La première chose à mettre en place, c’est le VPC avec un Cloud NAT pour que notre machine de patch puisse accéder à Internet sans besoin d’une IP publique directe (petit aspect sécurité basique).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
resource "google_compute_subnetwork" "subnetwork" {
name = var.subnet
ip_cidr_range = var.ip_cidr_range
region = var.region
network = google_compute_network.vpc.id
}
resource "google_compute_network" "vpc" {
name = var.vpc
auto_create_subnetworks = false
}
resource "google_compute_router" "router" {
name = "my-router"
region = google_compute_subnetwork.subnetwork.region
network = google_compute_network.vpc.id
bgp {
asn = 64514
}
}
resource "google_compute_router_nat" "nat" {
name = "my-router-nat"
router = google_compute_router.router.name
region = google_compute_router.router.region
nat_ip_allocate_option = "AUTO_ONLY"
source_subnetwork_ip_ranges_to_nat = "ALL_SUBNETWORKS_ALL_IP_RANGES"
log_config {
enable = true
filter = "ERRORS_ONLY"
}
}
|
Je ne me casse pas trop la tête, j’active les logs sur le NAT quand même, pour avoir des infos en cas de problème.
J’avais prévu de faire un truc un peu plus modulaire, mais en fait non, chaussette sale it is, bisous !

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
locals {
sa_compute_roles = [
"roles/artifactregistry.createOnPushWriter",
"roles/logging.logWriter",
"roles/batch.agentReporter"
]
sa_cloudfunction_roles = [
"roles/batch.jobsEditor",
"roles/cloudfunctions.invoker",
"roles/iam.serviceAccountUser"
]
}
resource "google_service_account" "sa_compute" {
account_id = "compute-patch-cve"
display_name = "compute patch cve"
}
resource "google_service_account" "sa_cloudfunction" {
account_id = "cf-trigger-patch-cve"
display_name = "cloudfunction trigger patch cve"
}
resource "google_project_iam_member" "sa_compute_bindings" {
for_each = toset(local.sa_compute_roles)
project = var.project
role = each.value
member = "serviceAccount:${google_service_account.sa_compute.email}"
}
resource "google_project_iam_member" "sa_cloudfunction_bindings" {
for_each = toset(local.sa_cloudfunction_roles)
project = var.project
role = each.value
member = "serviceAccount:${google_service_account.sa_cloudfunction.email}"
}
data "archive_file" "function_zip" {
type = "zip"
source_dir = "../../cloudfunction"
output_path = "${path.module}/function-source.zip"
excludes = [".venv", "Pipfile*"]
}
resource "google_storage_bucket" "bucket" {
name = "function-bucket-patch-cve"
location = "europe-west9"
uniform_bucket_level_access = true
}
resource "google_storage_bucket_object" "object" {
name = "${data.archive_file.function_zip.output_md5}.zip"
bucket = google_storage_bucket.bucket.name
source = "function-source.zip"
}
resource "google_cloudfunctions2_function" "function" {
name = "trigger_patch"
location = "europe-west9"
build_config {
runtime = "python312"
entry_point = "trigger_patch"
source {
storage_source {
bucket = google_storage_bucket.bucket.name
object = google_storage_bucket_object.object.name
}
}
}
service_config {
environment_variables = {
BATCH_PROJECT_NAME = "patch-container"
BATCH_REGION = "europe-west9"
BATCH_NETWORK = "projects/patch-container/global/networks/patch-vpc"
BATCH_SUBNETWORK = "projects/patch-container/regions/europe-west9/subnetworks/patch-subnetwork-europe-west9"
SA_BATCH_COMPUTE = google_service_account.sa_compute.email
BATCH_DOCKER_IMAGE = "europe-west9-docker.pkg.dev/patch-container/patch-container/patch-container:v0.0.2"
TARGET_REPO = "europe-west9-docker.pkg.dev/patch-container/patch-container"
LOG_EXECUTION_ID = "true"
}
service_account_email = google_service_account.sa_cloudfunction.email
}
}
|
Et paf, le bloc de canard ! C’est bientôt Noël, j’anticipe l’indigestion !

Donc, en vrac, on a :
- Un compte de service pour les autorisations accroché à mon compute de patch, il doit pouvoir faire du Container Registry, écrire des logs et reporter son état à Cloud Batch.
- Un compte de service pour la Cloud Function qui déclenche Cloud Batch, qui a le droit de s’invoquer, de faire des batchs et d’impliquer son service account de Cloud Batch (pour accrocher le service account compute de Cloud Batch).
- Une mécanique infernale avec du bucket et du zip, pour générer une archive qui change quand le code de la Cloud Function change, l’uploader dans un bucket et déployer la Cloud Function dans une nouvelle version.
La Cloud Function avec plein de paramètres (je m’en fous qu’ils soient exposés, je détruis le projet avant de publier).
Bon, c’est juste de la plomberie, mais c’est important d’avoir tout ça pour comprendre la mécanique et la configuration de la Cloud Function qui suit.
Pis là, je te mets le code de ma Cloud Function de l’enfer, qui va finalement déclencher mon Cloud Batch avec l’image Docker en paramètre.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
|
#!/bin/env python3
import functions_framework
import os
import sys
import json
import base64
import requests
from datetime import datetime
import google.auth
import google.auth.transport.requests
if not os.getenv("LOCAL_DEV", False):
import google.cloud.logging
client = google.cloud.logging.Client()
client.setup_logging()
import logging
logging.basicConfig(level=logging.INFO)
if not os.getenv("LOCAL_DEV", False):
logging.basicConfig(level=logging.DEBUG)
def get_auth_token() -> str:
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
return creds.token
def get_mandatory_env_var_or_exit() -> dict:
env_vars = [
"BATCH_PROJECT_NAME",
"BATCH_REGION",
"BATCH_NETWORK",
"BATCH_SUBNETWORK",
"SA_BATCH_COMPUTE",
"BATCH_DOCKER_IMAGE",
"TARGET_REPO",
]
checked_vars = {}
for var in env_vars:
checked_vars[var] = os.getenv(var)
if not checked_vars[var]:
message = (
f"env var {var} is required to run the application, fail to start."
)
logging.fatal(message)
sys.exit(-1)
return checked_vars
def trigger_cloud_batch_patch_image(docker_image, env_vars) -> int:
headers = {"Authorization": f"Bearer {get_auth_token()}"}
G image_tag = docker_image.split("/")[-1].replace(":", "-").replace(".", "-")
url = f"https://batch.googleapis.com/v1alpha/projects/{env_vars.get('BATCH_PROJECT_NAME')}/locations/{env_vars.get('BATCH_REGION')}/jobs?job_id=patch-{image_tag}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
batch = {
"taskGroups": [
{
"taskSpec": {
"runnables": [
{
"container": {
"imageUri": env_vars.get("BATCH_DOCKER_IMAGE"),
"entrypoint": "./patch-image.py",
"volumes": [
"/var/run/docker.sock:/var/run/docker.sock:rw",
"/sys/fs/cgroup:/sys/fs/cgroup:rw",
],
"options": "--privileged --cap-add=CAP_SETGID --cap-add=SETUID --cap-add=SYS_RESOURCE --cap-add=SYS_PTRACE --cap-add=DAC_OVERRIDE --cap-add=SYS_ADMIN",
},
"environment": {
"variables": {
"ORIGINAL_DOCKER_IMAGE": docker_image,
"TARGET_REPO": env_vars.get("TARGET_REPO"),
}
},
}
],
"computeResource": {"cpuMilli": 2000, "memoryMib": 16},
"maxRunDuration": "600s",
},
"taskCount": 1,
"parallelism": 1,
}
],
"allocationPolicy": {
"network": {
"networkInterfaces": [
{
"network": env_vars.get("BATCH_NETWORK"),
"subnetwork": env_vars.get("BATCH_SUBNETWORK"),
"noExternalIpAddress": True,
}
]
},
"instances": [{"policy": {"machineType": "e2-standard-4"}}],
"serviceAccount": {"email": env_vars.get("SA_BATCH_COMPUTE")},
},
"logsPolicy": {"destination": "CLOUD_LOGGING"},
}
logging.info(batch)
response = requests.post(url, headers=headers, json=batch, timeout=60)
logging.info(response.text)
logging.info(f"trigger cloudbatch status code : {response.status_code}")
return response.status_code
@functions_framework.http
def trigger_patch(request):
env_vars = get_mandatory_env_var_or_exit()
request_json = request.get_json(silent=True)
if request_json and "docker_image" in request_json:
docker_image = request_json["docker_image"]
else:
msg = "Missing required environment variable docker_image."
logging.error(msg)
return msg
return_code = trigger_cloud_batch_patch_image(docker_image, env_vars)
return str(return_code)
|
Le fichier des requirements que j’ai extrait de pipenv (ça, c’est si tu es assez fou pour essayer de le refaire marcher sur ton env GCP).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
-i https://pypi.org/simple
blinker==1.8.2; python_version >= '3.8'
cachetools==5.5.0; python_version >= '3.7'
certifi==2024.8.30; python_version >= '3.6'
charset-normalizer==3.4.0; python_version >= '3.7'
click==8.1.7; python_version >= '3.7'
cloudevents==1.11.0
deprecated==1.2.14; python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3'
deprecation==2.1.0
flask==3.0.3; python_version >= '3.8'
functions-framework==3.8.1
google-api-core[grpc]==2.21.0; python_version >= '3.7'
google-auth==2.35.0
google-cloud-appengine-logging==1.5.0; python_version >= '3.7'
google-cloud-audit-log==0.3.0; python_version >= '3.7'
google-cloud-core==2.4.1; python_version >= '3.7'
google-cloud-logging==3.11.3
googleapis-common-protos==1.65.0; python_version >= '3.7'
grpc-google-iam-v1==0.13.1; python_version >= '3.7'
grpcio==1.67.0
grpcio-status==1.67.0
gunicorn==23.0.0; platform_system != 'Windows'
idna==3.10; python_version >= '3.6'
importlib-metadata==8.4.0; python_version >= '3.8'
itsdangerous==2.2.0; python_version >= '3.8'
jinja2==3.1.4; python_version >= '3.7'
markupsafe==3.0.2; python_version >= '3.9'
opentelemetry-api==1.27.0; python_version >= '3.8'
packaging==24.1; python_version >= '3.8'
proto-plus==1.25.0; python_version >= '3.7'
protobuf==5.28.3; python_version >= '3.8'
pyasn1==0.6.1; python_version >= '3.8'
pyasn1-modules==0.4.1; python_version >= '3.8'
requests==2.32.3
rsa==4.9; python_version >= '3.6' and python_version < '4'
urllib3==2.2.3; python_version >= '3.8'
watchdog==5.0.3; python_version >= '3.9'
werkzeug==3.0.5; python_version >= '3.8'
wrapt==1.16.0; python_version >= '3.6'
zipp==3.20.2; python_version >= '3.8'
|
Donc, la seule “magie” qui peut rester dans le code, c’est dans le dictionnaire de configuration de la Cloud Function.
Sur la partie volume et configuration, le container Docker doit tourner avec des droits complètement pétés, parce qu’il utilise le daemon Docker dans le container qui le fait tourner.
Tout le reste, c’est de l’enrobage un peu simplet pour vérifier que les variables d’env sont configurées, parser le dict JSON envoyé en paramètre pour attraper l’image Docker.
Et tout ça, pour quoi finalement ? Pour la gloire de Satan, bien évidemment.
1
2
3
4
5
6
7
|
curl -m 70 -X POST https://europe-west9-patch-container.cloudfunctions.net/trigger_patch \
-H "Authorization: bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"docker_image": "memcached:1.6.31"
}'
200
|
Et ouais, ça fait 200, pas mal non ? C’est Français

Test sur 3 images
J’ai fait un tour sur Docker Hub pour sélectionner 3 images intéressantes pour démontrer mon système. Finalement, ce n’est pas si simple que ça : il me faut des images avec des CVE systèmes patchables et des CVE de libs patchables, pour démontrer que les libs systèmes sont patchées, mais pas les libs de code pour limiter la casse. Et le dernier critère, mais pas des moindres, des images officielles de produits connus et bien utilisés :)
J’ai donc choisi mes 3 starters Pokémon : Vault, Memcached et Alpine. Là, vous ne pouvez pas me dire que j’ai choisi les fonds de tiroir de Docker Hub sur des versions de 5 ans d’âge. Mais j’avoue que Docker Hub a fait un effort particulier pour renforcer la visibilité sur les images vulnérables et que c’était la chasse au trésor.
1
2
3
4
|
REPOSITORY TAG IMAGE ID CREATED SIZE
alpine 3.20.0 1d34ffeaf190 6 months ago 7.79MB
memcached 1.6.31 b047d324da06 2 months ago 84.8MB
vault 1.13.3 806d527c0cfb 8 months ago 255MB
|
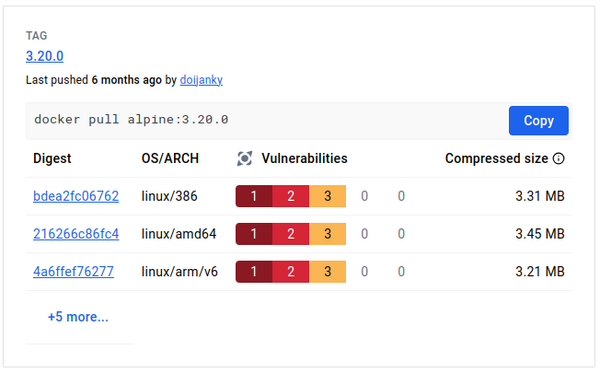
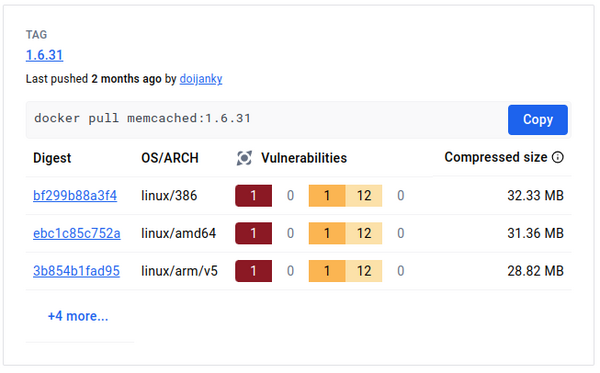
Je vous mets le rapport de sécurité digest de Docker Hub et après, on regarde en détail le post-traitement.
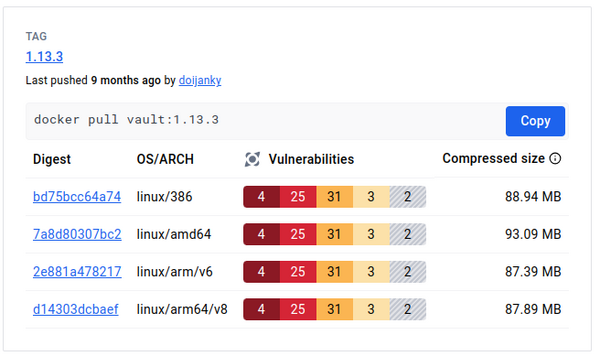
Donc, j’ai pris des images raisonnablement récentes avec des CVE système patchables.
Je lance ma moulinette et voilà les résultats que j’ai obtenus avec le scanner de vulnérabilités de tonton GCP.
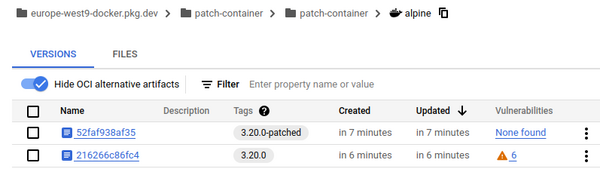
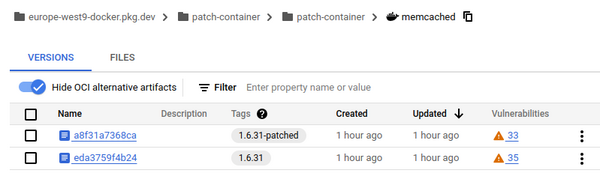
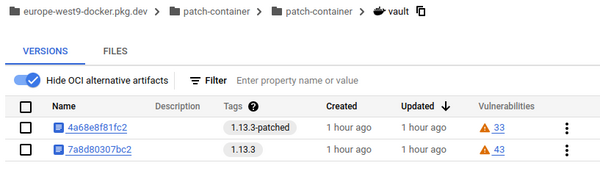
Maintenant, en regardant dans les détails des vulnérabilités restantes, vous allez comprendre pourquoi j’obtiens ces résultats.
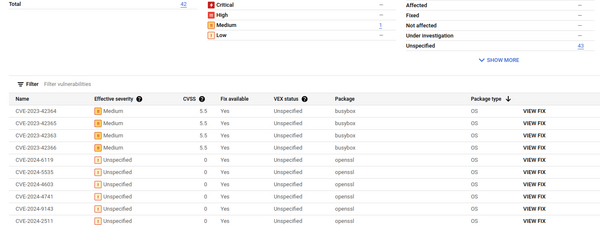
Sur l’image Alpine, c’est assez simple : seules des vulnérabilités d’OS patchables, et à la fin du traitement, toutes les libs ont été patchées.
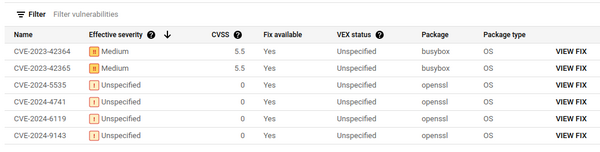
Sur l’image Memcached, seules 2 vulnérabilités OS sont patchables. On conserve donc forcément toutes les CVE existantes qui n’ont pas de patch.
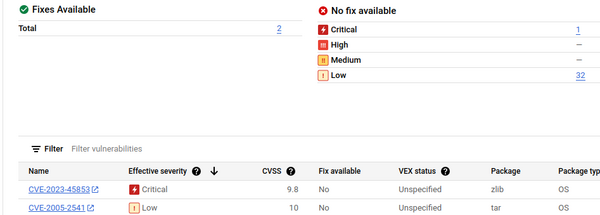
Sur l’image Vault, on a 42 CVE patchables, mais seulement 10 concernent des libs systèmes. On conserve donc les CVE liées aux libs et celles pour lesquelles aucun patch n’est disponible.
Limites du système et conclusion
Mon système offre une résolution partielle au problème douloureux de la gestion des CVE. Il fait un compromis en patchant les libs systèmes, qui sont très souvent des CVE liées à des libs C, lesquelles sont pénibles à patcher mais peu risquées à faire évoluer vers des versions plus récentes.
Les libs de code sont beaucoup plus à risque, car elles peuvent entraîner des breaking changes potentiels, compliqués à déboguer en raison de la mise à niveau de libs que l’on ne maîtrise pas.
Ce système apporte un moyen mécanique et standardisé de diminuer la surface des vulnérabilités (en s’attaquant à la classe de CVE la plus courante, on réduit de facto le nombre de vulnérabilités), mais il reste relativement complexe et un peu limité.
Nous n’adressons pas les CVE liées aux libs de code, donc le code vulnérable doit tout de même être audité et patché d’une autre manière, pourquoi pas avec Renovate, par exemple ? RenovateBot.
Il est possible d’introduire des changements cassants, donc il est essentiel de bien tester les nouvelles images patchées.
Mon système de patching est conçu principalement pour les images basées sur Debian et Alpine. Les images à base de Red Hat ou d’autres distributions plus exotiques ne sont actuellement pas prises en charge.
Le système décharge une partie de la difficulté de la mise à jour, mais il faut quand même allouer du temps et des personnes pour effectuer les changements d’images et les tests.
Néanmoins, il permet d’apporter une solution sur les images non construites par vos équipes, qui sont installées et utilisées pendant une longue période.
La meilleure solution pour avoir des images avec le moins de CVE reste de construire vos images vous-même et de contrôler drastiquement ce que vous y mettez…
Vous vous souvenez de l’image Docker que j’ai utilisée pour ce projet ?
Eh bien, je l’ai fait passer à la moulinette… et ce n’est pas glorieux, hahaha !

750 vulnérabilités, que des libs de code, ça craint, mouhahaha ! Eh bien, bravo et Joyeux Noël ! :)
