Cloudrun, il faut qu'on parle ... en privé
Salut les punkitos et les punkitas,
Aujourd’hui, on s’explique avec Cloud Run, mais on fait ça en privé 🥊🥊
Pour savoir de quoi on parle, un petit laïus de tonton GCP directement depuis la doc commerciale. Aujourd’hui, je me transforme en VRP !
Cloud Run est une plate-forme entièrement gérée qui vous permet d'exécuter votre code directement sur l'infrastructure évolutive de Google. Cloud Run est une solution simple, automatisée et conçue pour améliorer votre productivité.Donc, si je résume avec mes mots, tu viens avec ton container et tes variables d'environnement, et Cloud Run s'occupe du reste. Chausson, canapé, et terminé bonsoir !
Alors, les gens sont sceptiques, comme la fosse (jeu de mots tu sais). Un relent de méfiance et de résistance au changement souffle sur les plaines de la Bretagne armoricaine. Voici un florilège des affirmations que j’ai entendues au gré de mes interventions.
- Cloud Run, c’est dangereux, c’est exposé publiquement, on ne peut pas protéger facilement l’endpoint.
- Cloud Run, y a du cold start, c’est lent.
- Cloud Run, on ne peut pas le monitorer.
- Cloud Run, on ne sait pas où ça tourne et si quelqu’un écoute sur le réseau ?
- Cloud Run, on ne sait pas contrôler la facture, c’est trop imprévisible.
- Cloud Run, c’est trop limité pour mon besoin.
- Cloud Run, on ne peut pas faire des microservices.
- Cloud Run va me vendor locking, et ça sera compliqué d’en sortir.
Je vous propose de faire le tour des solutions qu’on peut mettre en place pour pallier ces différents “challenges” et une fois n’est pas coutume, de manière parfaitement non professionnelle et désorganisée.

Cloudrun en accès public
Si l’on lance Cloud Run pour la première fois avec l’image par défaut et la configuration par défaut, ainsi qu’une autorisation “Allow unauthenticated invocations”, on obtient un point d’accès public HTTPS et une belle image de licorne avec des confettis.
Dans un premier temps, on se demande bien pourquoi on utiliserait Cloud Run, puisque l’outil semble un peu simplet et limité.
La force de frappe principale de cet outil est, entre autres, sa simplicité et sa capacité d’autoscaling native. C’est une alternative plus que crédible pour remplacer GKE, à condition d’avoir des charges de travail adaptées aux contraintes de Cloud Run.
Bien sûr, tu pourrais faire le goret et mettre un alias DNS directement sur l’entrypoint autogénéré de Cloud Run. C’est laid, non sécurisé, et la porte ouverte à n’importe quoi !

On va voir les options qu’on a pour améliorer tout ça.
Première option : public load balancer + Cloud Armor
Le bon sens dicte de mettre en place un load balancer HTTP/HTTPS au minimum pour activer Cloud Armor et effectuer un filtrage des IPs autorisées.
Pour s’assurer que l’entrée par défaut de Cloud Run ne soit pas utilisée par des attaquants pour contourner ton load balancer, il faut configurer Cloud Run de manière à ce que son ingress ne soit accessible que depuis le réseau interne et le load balancer. Sélectionne “Ingress control -> Internal -> Allow traffic from external Application Load Balancers” dans le Cloud Run que tu veux protéger.
Dans le load balancer, configure un “backend service -> Serverless Network Endpoint Group -> Serverless network endpoint group”.
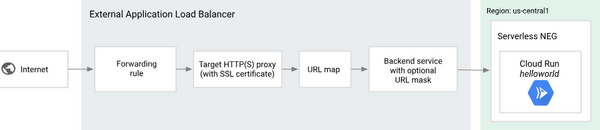
Oui j’ai piqué l’image chez google :)
Avec cette configuration minimale, on peut contrôler les accès publics à Cloud Run, et libre à toi ensuite d’implémenter un mécanisme d’authentification.
L’avantage est également que, avec cette méthode, on peut exposer plusieurs Cloud Run et router sur la même IP avec des URIs différentes. On peut ensuite agencer à la demande différentes loads et créer une infrastructure mixte, avec du compute, de la function, du Cloud Run et du GKE.
Ainsi, pas de contraintes pour utiliser uniquement Cloud Run, et la possibilité de passer de l’un à l’autre en fonction des besoins.
Deuxième option : public load balancer + IAP
En ce qui concerne l’authentification, Google met à disposition un mécanisme d’authentification Identity-Aware Proxy basé sur les comptes Google.
L’intérêt de l’IAP est de réaliser un contrôle d’accès avec les comptes Google au niveau applicatif, sans aucun effort de code.
On pourra ensuite décider d’un groupe de personnes autorisées dans l’application via un groupe Google.
Les contraintes de l’IAP sont les suivantes :
- Un enregistrement DNS qui pointe uniquement sur l’IP du load balancer.
- Un frontend HTTP et HTTPS sur le load balancer
- Ce qui implique forcément un certificat SSL sur le nom de domaine enregistré sur le load balancer.
- Le certificat peut être géré par Google, mais il faut forcément un global load balancer.
- Si on veut un regional load balancer, il faut un certificat tiers.
- Les backends ne doivent pas avoir de CDN activé.
C’est plus long et plus lourd à mettre en place, mais on a un accès public complet avec un moyen d’authentification fort et un certificat qui permet le chiffrement de la communication.
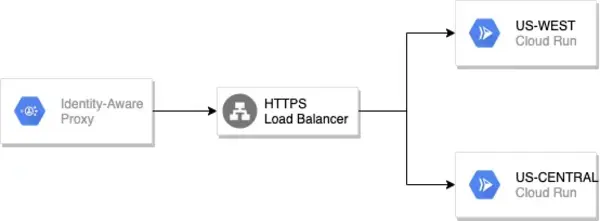
J’ai aussi piquer ce shéma en toute décontraction, c’est écoresponsable je recycle :)
Il ne faut pas le dire au Directeur des Systèmes d’Information de ton entreprise, il pourrait se vexer :) C’est un niveau de sécurité acceptable quand on n’est pas la DARPA !
La suite de l’article, c’est pour faire plaisir à ton DSI et donner des sous à Google en achetant des load balancers !
Cloud Run en Accès Privé
Et si je te disais qu’on peut faire du Cloud Run en accès privé, que tu peux contacter ton Cloud Run dans ton VPC avec de l’internal load balancing et des tables de blackjack ? Bon, c’est bien beau tout ça, mais peut-être que tu ne veux pas forcément exposer ton Cloud Run publiquement et que tu veux montrer pudiquement ton gros PHP seulement via un réseau privé ?
On s’adresse à des organisations un peu plus imposantes qui ont les moyens d’interconnecter GCP avec leur réseau privé d’entreprise. Ce n’est pas beaucoup plus compliqué que pour le public load balancer, c’est pratiquement la même chose.
La nuance importante, c’est qu’il va falloir un VPC dans la même région que le Cloud Run qu’on veut en accès privé et prévoir des subnets supplémentaires pour les IPs internes du load balancer et un truc de tambouille interne que Google appelle le readonly-proxy, pour faire fonctionner la mécanique interne du load balancing.
Si vous voulez un certificat SSL, il faudra l’uploader sur le load balancer interne et faire un enregistrement DNS interne Cloud DNS pour enregistrer l’adresse privée du load balancer et émerveiller vos utilisateurs internes.
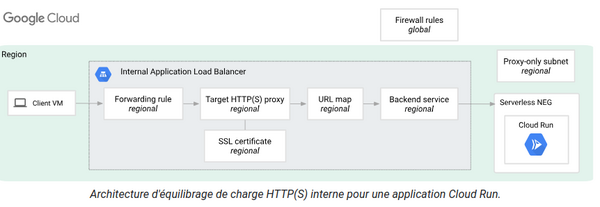
Aussi piqué chez Google, hey !
Cloud Run parle à Cloud Run ou sur n’importe quoi de privé
Si vous voulez discuter de manière privée depuis Cloud Run, c’est possible, mais attention, il y a une solution qui coûte un rein et une solution bien moins chère :) La solution moins chère n’étant pas disponible en global pour le moment, il faudra lâcher des pièces sur les zones non couvertes (coucou Paris) !
Deux secondes de votre attention : la solution qui coûte cher -> Utilisez des connecteurs Serverless VPC Access Tout pareil mais moins cher et plus récent -> Envoyez le trafic directement vers un VPC
Bon en vrai, c’est un peu plus subtil que ça, le connecteur est un peu plus sécurisé, nécessite des accès en plus et propose plus d’isolation réseau.
Je compte sur toi pour lire la doc si le besoin de private connection se fait sentir :)
Architecture 3 tiers avec Cloud Run
Finalement, tout ça n’est qu’une histoire de configuration. Rien ne t’empêche de faire un Cloud Run qui parle à d’autres Cloud Runs en privé et de faire une archi trois tiers.
Le frontend est exposé publiquement et parle au backend via une adresse publique. Le backend parle à des bases de données ou services tiers.
Du coup, on a bien les 3 couches : salades, tomates, oignons. Alors on arrête de dire que Cloud Run n’est pas sécurisé et qu’on ne peut pas faire du microservice ou des infras propres.
Hyper flemme de faire un schéma, alors j’ai demandé à bing image de m’en générer une …

Voici le prompt
global load balancer qui sert un cloudrun frontal le cloudrun frontal sert un internal load balancer qui sert des cloudrun en accès privé.
Tuning de Cloud Run
Ton service n’est pas appelé souvent ? Y a un cold start de malade à chaque fois que tu accèdes à ton appli ? Il faut configurer Cloud Run pour lui dire d’avoir un container allumé tout le temps.
Option : CPU is always allocated, minimum number of instance 1.
La planète ne te remercie pas, tu laisses allumée une machine qui ne fait rien, ce n’est pas fou. Mais imagine si c’était un GKE avec des nœuds énormes toujours actifs même si tes pods ne font rien ? Hahaha, le truc de ringards :’) En vrai, si tu as un service de prod, tu devrais activer au moins 1 pod pour réduire le cold start. En préprod/staging, c’est juste du gaspillage de ressources et d’argent.
Si tu as un gros Java, ou un truc qui met longtemps à démarrer qui tourne dans ton Cloud Run, il y a l’option Startup CPU boost, pour cramer plus de CPU au démarrage.
Si tu as peur de cramer ton budget à cause de l’autoscaling, tu peux réduire les limites par défaut de scheduling qui vont de 0 à 100 containers.
Tu peux réduire le nombre de requêtes max par container pour éviter de congestionner tes containers quand ils sont chargés.
N’oublie pas de mettre un service account avec les permissions adaptées sur tes Cloud Run pour réduire la surface d’attaques.

Contraintes de Cloud Run
Voici les quelques cas d’usages où Cloud Run n’est pas recommandé.
Cloud Run est conçu pour répondre sur événement ou sur requêtes HTTP.
Voici les choses qui ne supportent pas :
- Les connexions persistantes et de gRPC (ironique parce que c’est une tech Google).
- Les sticky sessions, puisqu’il ne persiste rien et que les sticky sessions c’est un peu ringard.
- Service stateful nécessitant un service allumé en permanence.
- Application qui écrit sur disques persistants.
- Application qui a des requêtes HTTP de très longue durée
- Genre plus d’une heure hihihi, mais pourquoi tu fais ça dans Cloud Run web ? Utilise Cloud Run en mode job, c’est fait pour ça …
- Multiprocessing, asynchronisme et tâches de fond (puisqu’il répond sur HTTP et s’éteint quand le serveur répond un code HTTP).
Du coup, si tu as des applications legacy avec des contraintes lourdes de l’ancien monde, c’est mort, mais à mon sens, pas de bonne raison de ne pas faire du Cloud Run en priorité.
Bon, ok, encore un ou deux trucs un peu chiants avec Cloud Run
L’observabilité est possible, mais il faut obligatoirement passer par Stackdriver, qui n’évolue pas tant et qui est toujours aussi désolant de nullité. On commence à percevoir une volonté de pousser du Prometheus managé et de l’interopérabilité avec Grafana, et ça va être un game changer :)
L’opentracing dans Google Trace est actif par défaut pour certains langages, et c’est vraiment pas mal, même s’il n’a pas de continuité fine jusqu’aux bases de données.
Cloud Logging est efficace mais relativement compliqué dès qu’on commence à essayer de faire des requêtes précises et complexes.
La facturation est à la consommation de ressources, il est difficile d’avoir une prédictivité des coûts, mais la consommation à la demande nous permet de nous interroger vraiment sur ce que l’on consomme et donne moins de scrupules à dégager des trucs.
En somme, sur les nouveaux projets, faites du Cloud Run, la planète vous remercie. Les sysadmins un peu moins, mais au moins, ils auront du temps pour s’occuper des bases de données Oracle et MSSQL :)
